
Norbert Oster
Dr.-Ing. Norbert Oster, Akad. ORat

Computer Science Department
Programming Systems Group (Informatik 2)
Martensstr. 3
91058 Erlangen
Germany
- Phone number: +49 9131 85-28995
- Fax number: +49 9131 85-28809
- Email: norbert.oster@fau.de
- Website: https://www.ps.tf.fau.de/en/mitarbeitende/oster/
Student contact hour
Prearrange an appointment by email.
Projects
-
Verification and validation in industrial practice
(Own Funds)
Term: since 01.01.2022Detection of flaky tests based on software version control data and test execution history
Regression tests are carried out often and because of their volume also fully automatically. They are intended to ensure that changes to individual components of a software system do not have any unexpected side effects on the behavior of subsystems that they should not affect. However, even if a test case executes only unmodified code, it can still sometimes succeed and sometimes fail. This so-called "flaky" behavior can have different reasons, including race conditions due to concurrent execution or temporarily unavailable resources (e.g., network or databases). Flaky tests are a nuisance to the testing process in every respect, because they slow down or even interrupt the entire test execution and they undermine the confidence in the test results: if a test run is successful, it cannot necessarily be concluded that the program is really error-free, and if the test fails, expensive resources may have to be invested to reproduce and possibly fix the problem.
The easiest way to detect test flakyness is to repeatedly run test cases on the identical code base until the test result changes or there is a reasonable statistical confidence that the test is non-flaky. However, this is rarely possible in an industrial environment, as integration or system tests can be extremely time-consuming and resource-demanding, e.g., because they require the availability of special test hardware. For this reason, it is desirable to classify test cases with regard to their flakyness without repeated re-execution, but instead to only use the information already available from the preceding development and test phases.
In 2022, we implemented and compare various so-called black box methods for detecting test flakyness and evaluated them in a real industrial test process with 200 test cases. We classify test cases exclusively on the basis of generally available information from version control systems and test execution tools, i.e., in particular without an extensive analysis of the code base and without monitoring of the test coverage, which would in most cases be impossible for embedded systems anyway. From the 122 available indicators (including the test execution time, the number of lines of code, or the number of changed lines of code in the last 3, 14, and 54 days) we extracted different subsets and examined their suitability for detecting test flakyness using different techniques. The methods applied on the feature subsets include rule-based methods (e.g., "a test is flaky if it has failed at least five times within the observation window, but not five times in a row"), empirical evaluations (including the computation of the cumulative weighted "flip rate", i.e., the frequency of alternating between test success and failure) as well as various methods from the domain of machine learning (e.g., classification trees, random forest, or multi-layer perceptrons). By using AI-based classifiers together with the SHAP approach for explaining AI models we determined the four most important indicators ("features") for detecting test flakyness in the industrial environment under consideration. The so-called "gradient boosting" with the complete set of indicators has proven to be optimal (with an F1-score of 96.5%). The same method with only four selected features achieved just marginally lower accuracy and recall values (with almost the same F1 score).
Synergies of a-priori and a-posteriori analysis methods to explain artificial intelligence
Artificial intelligence is rapidly conquering more domains of everyday life and machines make more critical decisions: braking or evasive maneuvers in autonomous driving, credit(un)worthiness of individuals or companies, diagnosis of diseases from various examination results (e.g., cancer detection from CT/MRT scans), and many more. In order for such a system to receive trust in a real-life productive setting, it must be ensured and proven that the learned decision rules are correct and reflect reality. The training of a machine model itself is a very resource-intensive process and the quality of the result can usually only be quantified afterwards with extremely great effort and well-founded specialist knowledge. The success and quality of the learned model not only depends on the choice of a particular AI method, but is also strongly influenced by the magnitude and quality of the training data.
In 2022, we therefore examined which qualitative and quantitative properties an input set must have ("a priori evaluation") in order to achieve a good AI model ("a posteriori evaluation"). For this purpose, we compared various evaluation criteria from the literature and we defined four basic indicators based on them: representativeness, freedom from redundancy, completeness, and correctness. The associated metrics allow a quantitative evaluation of the training data in advance of preparing the model. To investigate the impact of poor training data on an AI model, we experimented with the so-called "dSprites" dataset, a popular generator for image files used in the evaluation of image resp. pattern recognition methods. This way, we generated different training data sets that differ in exactly one of the four basic indicators and have quantitatively different "a priori quality". We used all of them to train two different AI models: Random Forest and Convolutional Neural Networks. Finally, we quantitatively evaluated the quality of the classification by the respective model using the usual statistical measures (accuracy, precision, recall, F1-score). In addition, we used SHAP (a method for explaining AI models) to determine the reasons for any misclassification in cases of poor data quality. As expected, the model quality highly correlates with the training data quality: the better the latter is with regard to the four basic indicators, the more precise is the classification of unknown data by the trained models. However, a noteworthy discovery has emerged while experimenting with the lack of redundancy: If a trained model is evaluated with completely new/unknown inputs, the accuracy of the classification is sometimes significantly worse than if the available input data is split into a training and an evaluation data set: In the latter case, the a posteriori evaluation of the trained AI system misleadingly suggests a higher model quality.
Few-Shot Out-of-Domain Detection in Natural Language Processing Applications
Natural language processing (NLP for short) using artificial intelligence has many areas of application, e.g., telephone or written dialogue systems (so-called chat bots) that provide cinema information, book a ticket, take sick leave, or answer various questions arising during certain industrial processes. Such chat bots are often also involved in social media, e.g., to recognize critical statements and to moderate them if necessary. With increasing progress in the field of artificial intelligence in general and NLP in particular, self-learning models are spreading that dynamically (and therefore mostly unsupervised) supplement their technical and linguistic knowledge from concrete practical use. But such approaches are susceptible to intentional or unintentional malicious disguise. Examples from industrial practice have shown that chat bots quickly "learn" for instance racist statements in social networks and then make dangerous extremist statements. It is therefore of central importance that NLP-based models are able to distinguish between valid "In-Domain (ID)" and invalid "Out-Of-Domain (OOD)" data (i.e., both inputs and outputs). However, the developers of an NLP system need an immense amount of ID and OOD training data for the initial training of the AI model. While the former are already difficult to find in sufficient quantities, the a priori choice of the latter is usually hardly possible in a meaningful way.
In 2022, we therefore examined and compared different approaches to OOD detection that work with little to no training data at all (hence called "few-shot"). The currently best and most widespread, transformer-based and pre-trained language model RoBERTa served as the basis for the experimental evaluation. To improve the OOD detection, we applied "fine-tuning" and examined how reliable the adaptation of a pre-trained model to a specific domain can be done. In addition, we implemented various scoring methods and evaluated them to determine threshold values for the classification of ID and OOD data. To solve the problem of missing training data, we also evaluated a technique called "data augmentation": with little effort GPT3 ("Generative Pretrained Transformer 3", an autoregressive language model that uses deep learning to generate human-like text) can generate additional and safe ID and OOD data to train and evaluate NLP models.
Application of weighted combinatorics in the generation and selection of parameters and their representatives in software testing
Some functional testing methods (so-called black box tests), such as the equivalence class testing or boundary value analysis, focus on individual parameters. For these parameters, they determine representatives (values or classes of values) to be considered in the test. Since not just a single parameter but several parameters are usually required to perform such tests, representatives of several parameters must be combined with each other to be used for test execution. Well-understood combinatorial methods such as "All Combinations", "Pair-wise" or "Each choice" are usually used for this purpose. They do not take into account information about weights (attributes such as importance or priority) of the parameters and equivalence class representatives, which would affect the number of associated test cases (e.g. due to importance) or their recommended order (in terms of prioritization). In addition, in the case of the equivalence class method, there are scenarios in which a combination of several invalid classes in a single test case could optionally be explicitly desired, completely undesirable or limited to a certain number in order to specifically test fault combinations on the one hand, but also to simplify fault localization on the other. There is reason to believe that by considering such weights and options, more targeted and ultimately more efficient test cases can be derived.
In 2023, we evaluated and compared known combinatorial approaches that take into account weights when combining parameters or their values. Based on this, we developed a novel approach to generate and select parameters and their representatives in software testing. The proposed method uses a weighting system to prioritize the individual parameters, their equivalence classes and concrete representatives, in a set of test cases. If necessary, their interactions can also be specifically weighted in order to allow certain combinations to occur more frequently in the generated test cases. To evaluate the approach, we defined a suitable prototype data structure that represents the various weightings. We then implemented evaluation functions for existing sets of test cases in order to quantitatively determine how well such a test case set satisfies the specified combinatorics. In a further step, we used these evaluation functions in combination with various systematic methods and heuristics (SAT solver Z3, simulated annealing, and genetic algorithms) to generate new test cases that match the weighting or to optimize existing sets by adding missing test cases. Simulated Annealing was the fastest and gave the best results in the test series. Although the SAT-approach worked well for small problems, it was no longer practical for larger test cases due to exorbitant runtimes.
-
Promote computer science as the basis for successful STEM studies along the entire education chain.
(Third Party Funds Single)
Term: 01.11.2019 - 31.10.2022
Funding source: Bayerisches Staatsministerium für Wissenschaft und Kunst (StMWK) (seit 2018)
URL: https://www.ddi.tf.fau.de/forschung/laufende-projekte/cs4mints-informatik-als-grundlage-eines-erfolgreichen-mint-studiums-entlanProgressive digitalization is changing not only the job market but also the educational landscape. With funding from the DigitalPakt Schule and in detail from the BAYERN DIGITAL II program, serious changes in computer science education are being driven forward, which entail new challenges at the various levels of education.
The CS4MINTS project addresses these challenges along with the educational levels and ties in with measures already launched as part of the MINTerAKTIV project, such as strengthening the encounter of increasing student heterogeneity in the introductory computer science course.
For example, for promoting gifted students, the Frühstudium in computer science is actively promoted for girls, and the offer is explicitly expanded. A significant increase in the proportion of women in computer science is to be achieved in the long term through early action against gender-specific stereotypes regarding computer science and an expansion of the training program to include gender-sensitive computer science instruction in all types of schools.
The expansion of the compulsory subject of computer science in all schools also creates a great need for suitable teaching concepts and a strengthening of teacher training. For this purpose, a regional network is to be established during the project period to provide university-developed and evaluated teaching ideas for strengthening STEM in the curricular and extra-curricular settings.
In 2020, we began the initial piloting of the design to automate feedback in the introductory programming exercises. For this purpose, the return values of the JUnit tests of students' solutions were analyzed, and possible sources of errors were investigated. The next step is to work out a way to infer programming errors or student misconceptions based on these return values. Finally, these efforts aim to provide the students with automatically generated, competence-oriented feedback available to them after the programming tasks have been submitted (or, if necessary, already during the development phase). The feedback should show where errors occurred in the program code and point out possible causes.
Concerning handling heterogeneity, we have compared the Repetitorium Informatik (RIP) course content with the Bavarian curriculum of different school types in 2020. Subsequently, the content must be adapted so that first-year students from the most diverse educational backgrounds have equal opportunities to identify possible deficits through the Repetitorium and remedy them. Besides, a daily programming consultation hour was set up for the first time during the Repetitorium in the winter term 2020. Here, participants were able to ask questions and receive feedback on the assignments.
For many students, the initial steps of learning to program is one of the major challenges at the beginning of their studies. In order to provide additional feedback to novice programmers, we have designed and piloted the Feedback+ project in 2021. Within the framework of Feedback+, students have the opportunity to document problems that occur during the processing of the exercises or during the setup/use of the programming environment. They can also receive additional feedback in individual consultation sessions (weekly). For this purpose, we have set up a StudOn environment in which problems can be systematically documented. An initial evaluation in the form of individual interviews with the participating students received consistently positive feedback and is motivation to continue the project.
-
Computer Science basics as an essential building block of modern STEM field curricula
(Third Party Funds Single)
Term: 01.10.2016 - 30.09.2019
Funding source: Bayerisches Staatsministerium für Bildung und Kultus, Wissenschaft und Kunst (ab 10/2013)
URL: https://www2.cs.fau.de/research/GIFzuMINTS/The increasing digitalization of all areas of science and life render competencies in the foundations of computer science essential for all tech students and more. For the success of their academic studies, often their courses, especially the introductory ones, are problematic hurdles that may lead to a dropout.
For this reason, this project expands the support that students get while they are still at school, while transitioning from school to university, and during the introductory phase. To address the study orientation phase when future STEM students are still at school, we (a) use our regional and national contacts to provide support for seminars and we (b) offer advanced training for teachers as they act as multipliers when future students choose their degrees. To address the transition from school to university, we focus on the fact that freshmen show up with different previous knowledge. We offer revision courses to bring the students onto the same page, i.e., to make their knowledge more homogeneous. In the introductory phase, special intensification exercises and tutoring that take heterogeneity into account strive to lower the dropout rates.
In 2018, one focus was to evaluate the effectiveness of our measures: the increased range of exercise groups, the more extensive support from the tutors, the correlation between exercise attendence and dropout rate, the effects of participation in the revision courses on the performance in the exercises and in the exam, etc.
In order to attract and qualify teachers as multipliers, we expanded the range of advanced training courses for teachers: we demonstrated innovative approaches, examples and content for teaching so that the participants can pass on to their students what they have learned themselves.
To quantitatively and qualitatively improve the W seminar papers written in computer science at school we compiled a 24-page brochure and sent it to schools in surrounding counties. This brochure supports teachers in the design and implementation of W seminars in IT by providing subject suggestions, tips, and a checklist for students.
The GIFzuMINTS project ended in 2019 with a special highlight: On May 20, 2019, the Bavarian Minister of State for Science and Art, Bernd Sibler, and the deputy general manager of vbw bayme vbm, Dr. Christof Prechtl, visited us in a status meeting. Minister Bernd Sibler was impressed: "The concept of the FAU is perfectly tailored to the requirements of a degree in computer science. The young students are supported from the very beginning immediately after finishing school. That is exactly our concern, which we pursue with MINTerAKTIV: We want every student to receive the support she/he needs to successfully complete his/her academic studies."
By the end of the project, the measures developed and implemented were thoroughly evaluated and established as permanent offers. The revision course on computer science was transformed into a continuous virtual offer for self-study and updated to the latest state of the art. The course for talented students that prepares them to participate in international programming competitions was expanded and set up as a formal module of the curriculum. In order to ensure that the measures sustain, we applied for subsequent funding, which has already been approved as CS4MINTS. -
Techniques and tools for iterative development and optimization of software for embedded multicore systems
(Third Party Funds Single)
Term: 15.10.2012 - 30.11.2014
Funding source: Bayerisches Staatsministerium für Wirtschaft, Infrastruktur, Verkehr und Technologie (StMWIVT) (bis 09/2013)Multicore processors are of rising importance in embedded systems as these processors offer high performance while maintaining low power consumption. Developing parallel software for these platforms poses new challenges for many industrial sectors because established tools and software libraries are not multicore enabled. The efficient development, optimization and testing of multicore-software is still open research, especially for reliable real-time embedded systems.In the multi-partner project "WEMUCS" [http://www.multicore-tools.de/] new methods and tools for efficient iterative development, optimization, and testing of multicore software have been created over the past two years. Innovative tools and technologies for modeling, simulation, visualization, tracing, and testing have been developed and integrated into a single tool chain. Using case studies from different industries (automotive, telecommunications, industry automation) these tools were evaluated and improved.
Although several well-known methods for test case generation and best practice coverage measures for classical single-core applications exist, no such methods for multi-core software have established themselves yet. Unfortunately, it is the interaction of concurrent threads that can cause faults that cannot be discovered by testing the individual threads in isolation. As part of the WEMUCS project (more precisely: work package AP3 [http://www.multicore-tools.de/de/test.html]) and based on an industrial size case study, we developed a generic technique (called a "testing pipeline" below) that systematically creates test cases to find and analyze the impact of concurrent side effects.
To evaluate the new testing pipeline (including the automated parallelization of sequential code) on real world examples, our project partner Siemens created a complete model of a large luggage conveyor belt, including the code to control the belt. Such a luggage conveyor can be found at every airport. The case study's model is used to automatically derive luggage conveyor belt systems of different sizes, i.e., built from an arbitrary number of feeder or outlet belts. The hardware of the conveyor belt is emulated on the SIMIT simulation tool from Siemens and the control software (written in the programming language AWL) runs on a software-based PLC.
The first step of the testing pipeline converts the AWL code into a more comprehensible and human-readable programming language called HLL. We have completed this converter during this reporting period. In step two, our tool then transforms previously sequential parts of the AWL code into HLL units that are executed in parallel. When applied to a luggage conveyor belt system built from eight feeders, eight outlets and an inteconnecting circular belt of straight and curved segments, our tool automatically transcoded 11.704 lines of sequential AWL code into 34 KB of parallel HLL code.
In step three another tool developed by the chair then analyzes the HLL code and automatically generates a testing model. This model represents the interprocedural control flow of the concurrent subroutines and also holds all the thread switches that might be relevant for testing. The testing model consists of a set of hierarchically organized UML activities (currently encoded as an XMI document that can be imported into Enterprise Architect by Sparx Systems). When applied to the case study outlined above, our tool automatically generates 103 UML activity diagrams (with 1,302 nodes and 2,581 edges).
Step four is optional. The tester can manually adapt the testing model as needed (e.g. by changing priorities or inserting additional verification points). Then the completed model can be loaded into the MBTsuite tool, a model-based testing tool developed by our project partner sepp.med GmbH. This tool is highly configurable to generate test cases that cover as many parts of the testing model as possible. We ran MBTsuite on a standard PC and applied it to the testing model of our case study; within six minutes MBTSuite generated a highly optimized test set consisting of only 10 test cases that nevertheless cover 99% of the nodes and 78% of the edges.
In cooperation with our project partner sepp.med GmbH we built two export modules for the above-mentioned MBTsuite. One module outputs the generated test cases as a human-readable spreadsheet, the other module outputs an executable test set in the Java language. The exported spreadsheet contains one individual sheet per test case, with one column per thread. The rows visualize the thread interleaving that gets tested. The Java file holds a Java class with a test method per test case. Every method holds a sequence of test steps that discretely control thread interleavings. This way, each test case execution leads to a unique and reproducible execution of the parallel System Under Test (SUT) written in HLL. Each run of a test instructs our HLL emulator to load and initialize the SUT and each subsequent test step instructs the HLL emulator to execute a certain set of instructions from a certain thread. During this fully controlled execution, each test case emits a detailed protocol of its execution for the final visualization step.
A plug-in from sepp.med that creates a visualization layer in Enterprise Architect's UML editor visualizes the resulting log file. Colored nodes and edges tell the user which control flow paths a test has covered. If a test case "fails" (if a race condition or a logic error is found in the tested program), its graphical trace ends at the failing statement. The tester can then follow the control flow back in time in order to understand the underlying reason for the failure.
We have implemented a prototype of the full testing pipeline and demonstrated its applicability to an industrial size case study. This tool is a major contribution to testing concurrent code for embedded systems. It is a contribution of the Programming Systems Group to the "ESI initiative" [http://www.esi-anwendungszentrum.de].
-
Inter-Thread Testing
(Own Funds)
Term: 01.01.2012 - 31.12.2013In order to achieve higher computing performance, microprocessor manufacturers do not try to achieve faster clock speed anymore - on the contrary: the absolute number of cycles has even decreased, while the number of independent processing units (cores) per processor is continually increased. Due to this evolution, developers must learn to think outside the box: The only way to make their applications faster (in terms of efficiency) is to modularize their programs such that independent sections of code execute concurrently. Unfortunately, present-day systems have reached a level of functional complexity, such that even software for sequential execution is significantly error-prone - the parallelization for multiple cores adds yet another dimension to the non-functional complexity. Although research in the field of software engineering emerged several different quality assurance measures, there are still very few effective methods for testing concurrent applications, as the broad emergence of multi-core systems is relatively young.
This project aims to fill that gap by providing an automated test system. First of all, a testing criteria hierarchy is needed, which provides different coverage metrics tightly tailored to the concept of concurrency. Whilst for example branch coverage for sequential programs requires the execution of each program branch during the test (i.e. making the condition of an if-statements both true and false - even if there is no explicit else branch), a thorough test completion criterion for concurrent applications must demand for the systematic execution of all relevant thread interleavings (i.e. all possibly occurring orderings of statements, where two threads may modify a shared memory area). A testing criterion defines the properties of the 'final' test set only, but does not provide any support for identifying individual test cases. In contrast to testing sequentially executed code, test scenarios for parallel applications must also comprise control information for deterministically steering the execution of the TUT (Threads Under Test).
In 2012, a framework for Java has been developed, which automatically generates such control structures for TUT. The tester must provide the bytecode of his application only; further details such as source code or restrictions of the test scenario selection are optional. The approach uses aspect-oriented programming techniques to enclose memory access statements (reads or writes of variables, responsible for typical race conditions) with automatically generated advices. After weaving the aspects into the SUT (System Under Test), variable accesses are intercepted at runtime, the execution of the corresponding thread is halted until the desired test scenario is reached, and the conflicting threads are reactivated in the order imposed by the given test scenario. In order to demonstrate the functionality, some naive sequence control strategies were implemented, e.g. alternately granting access to shared variables from different threads.
In 2013, the prototypical implementation of the InThreaT framework has been reengineered as an Eclipse plugin. This way, our approach can also be applied in a multi-project environment and the required functionality integrates seamlessly into the development environment (IDE) familiar to programmers and testers. In addition, the configuration effort required from the tester could be reduced, as e.g. selecting and persisting the interesting points of interleaving also became intuitively usable parts of the IDE. In order to automatically explore all relevant interleavings, we need an infrastructure to enrich functional test cases with control information, required to systematically (re)execute individual test cases. In 2013, such an approach for JUnit has been evaluated and implemented prototypically, which allows to mark individual test cases or whole test classes with adequate annotations.
-
Automatische Testdatengenerierung zur Unterstützung inkrementeller modell- und codebasierter Testprozesse für hochzuverlässige Softwaresysteme
(Third Party Funds Single)
Term: 01.03.2006 - 31.10.2009
Funding source: Bayerisches Staatsministerium für Wirtschaft, Infrastruktur, Verkehr und Technologie (StMWIVT) (bis 09/2013)Das Vorhaben mit dem Verbundpartner AFRA GmbH verfolgte das Ziel, deutlich über den Stand der Technik hinaus die Testphase hochzuverlässiger, insbesondere sicherheitskritischer Software zu automatisieren, um dadurch bei reduzierten Kosten die Erkennung von Restfehlern in komplexer Software zu erhöhen.Im Rahmen des vom Freistaat Bayern als Bestandteil der Software Offensive Bayern geförderten Vorhabens wurden neue Verfahren zur automatischen Testunterstützung entwickelt und in entsprechende Werkzeuge umgesetzt. Diese Verfahren ermöglichen eine signifikante Reduzierung des erforderlichen Testaufwands in den frühen Entwurfsphasen und erlauben, den Bedarf ergänzender, auf Codebetrachtungen basierender Überprüfungen rechtzeitig festzustellen. Die automatisierte Testprozedur wurde im realen medizintechnischen Umfeld beim Pilotpartner Siemens Medical Solutions erprobt.
Das Projekt war in zwei Teile gegliedert. Der erste Teil betrachtete die automatische Testdatengenerierung auf Komponentenebene, während der zweite Teil den Integrationsaspekt von Komponenten in den Vordergrund stellte und Verfahren zur Automatisierung des Integrationstests entwickelte. In beiden Fällen wurde ein am Lehrstuhl auf Codeebene bereits erfolgreich umgesetzte Testkonzept auf Modellebene übertragen.
Die erzielten Ergebnisse und Einsichten bildeten die Grundlage der Dissertation "Automatische Optimierung und Evaluierung modellbasierter Testfälle für den Komponenten- und Integrationstest" von Herrn Dr.-Ing. Florin Pinte.
Current courses
Testen von Softwaresystemen
Basic data
| Title | Testen von Softwaresystemen |
|---|---|
| Short text | TSWS |
| Module frequency | nur im Sommersemester |
| Semester hours per week | 4 |
Parallel groups / dates
1. Parallelgruppe
| Semester hours per week | 4 |
|---|---|
| Teaching language | German |
| Responsible |
Dr. Klaudia Dussa-Zieger Dr.-Ing. Norbert Oster |
| Date and Time | Start date - End date | Cancellation date | Lecturer(s) | Comment | Room |
|---|---|---|---|---|---|
| wöchentlich Tue, 16:15 - 17:45 | 16.04.2024 - 16.07.2024 | 21.05.2024 |
|
11302.02.135 | |
| wöchentlich Wed, 16:15 - 17:45 | 17.04.2024 - 17.07.2024 | 01.05.2024 |
|
11302.02.135 |
Publications
2023
- , , , , :
Practical Flaky Test Prediction using Common Code Evolution and Test History Data
16th IEEE International Conference on Software Testing, Verification and Validation, ICST 2023 (Dublin, 16.04.2023 - 20.04.2023)
In: IEEE (ed.): Proceedings - 2023 IEEE 16th International Conference on Software Testing, Verification and Validation, ICST 2023 2023
DOI: 10.1109/ICST57152.2023.00028
BibTeX: Download - , , , , :
Practical Flaky Test Prediction using Common Code Evolution and Test History Data [replication package]
figshare (2023)
DOI: 10.6084/m9.figshare.21363075
BibTeX: Download
(online publication)
2020
- , , :
MutantDistiller: Using Symbolic Execution for Automatic Detection of Equivalent Mutants and Generation of Mutant Killing Tests
15th International Workshop on Mutation Analysis (Mutation 2020) (Porto, 24.10.2020 - 24.10.2020)
In: 2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW) 2020
DOI: 10.1109/ICSTW50294.2020.00055
URL: https://mutation-workshop.github.io/2020/
BibTeX: Download
2017
- , , :
AuDoscore: Automatic Grading of Java or Scala Homework
Third Workshop "Automatische Bewertung von Programmieraufgaben" (ABP 2017) (Potsdam, 05.10.2017 - 06.10.2017)
In: Sven Strickroth Oliver Müller Michael Striewe (ed.): Proceedings of the Third Workshop "Automatische Bewertung von Programmieraufgaben" (ABP 2017) 2017
Open Access: http://ceur-ws.org/Vol-2015/ABP2017_paper_01.pdf
URL: http://ceur-ws.org/Vol-2015/ABP2017_paper_01.pdf
BibTeX: Download
2011
- , :
Structural Equivalence Partition and Boundary Testing
Software Engineering 2011 - Fachtagung des GI-Fachbereichs Softwaretechnik (Karlsruhe, 24.02.2011 - 25.02.2011)
In: Ralf Reussner, Matthias Grund, Andreas Oberweis, Walter Tichy (ed.): Lecture Notes in Informatics (LNI), P-183, Bonn: 2011
URL: https://www2.cs.fau.de/publication/download/SE2011-OsterPhilippsen-SEBT.pdf
BibTeX: Download
2008
- , , , :
Automatische Generierung optimaler modellbasierter Regressionstests
Workshop on Model-Based Testing (MoTes 2008) (München, 08.09.2008 - 13.09.2008)
In: Heinz-Gerd Hegering, Axel Lehmann, Hans Jürgen Ohlbach, Christian Scheideler (ed.): INFORMATIK 2008 - Beherrschbare Systeme dank Informatik (Band 1), Bonn: 2008
BibTeX: Download - , , :
Techniques and Tools for the Automatic Generation of Optimal Test Data at Code, Model and Interface Level
30th International Conference on Software Engineering (ICSE 2008) (Leipzig, 10.05.2008 - 18.05.2008)
In: Companion of the 30th international conference on Software engineering (ICSE Companion '08), New York, NY, USA: 2008
DOI: 10.1145/1370175.1370191
URL: http://dl.acm.org/ft_gateway.cfm?id=1370191
BibTeX: Download - , , :
Automatic Generation of Optimized Integration Test Data by Genetic Algorithms
Software Engineering 2008 - Workshop "Testmethoden für Software - Von der Forschung in die Praxis" (München, 19.02.2008 - 19.02.2008)
In: Walid Maalej, Bernd Bruegge (ed.): Software Engineering 2008 - Workshopband, Bonn: 2008
URL: http://www11.informatik.uni-erlangen.de/Forschung/Publikationen/TESO%202008.pdf
BibTeX: Download - , , :
White and Grey-Box Verification and Validation Approaches for Safety- and Security-Critical Software Systems
In: Information Security Technical Report 13 (2008), p. 10-16
ISSN: 1363-4127
DOI: 10.1016/j.istr.2008.03.002
URL: http://www.sciencedirect.com/science/article/pii/S1363412708000071
BibTeX: Download - , , :
Qualität und Zuverlässigkeit im Software Engineering
In: Zeitschrift für wirtschaftlichen Fabrikbetrieb 103 (2008), p. 407-412
ISSN: 0932-0482
URL: http://www.zwf-online.de/ZW101296
BibTeX: Download
2007
- :
Automatische Generierung optimaler struktureller Testdaten für objekt-orientierte Software mittels multi-objektiver Metaheuristiken (Dissertation, 2007)
URL: https://www.ps.tf.fau.de/files/2020/04/norbertoster_dissertation2007.pdf
BibTeX: Download - , :
Automatische Testdatengenerierung mittels multi-objektiver Optimierung
Software Engineering 2007 (Hamburg, 27.03.2007 - 30.03.2007)
In: Wolf-Gideon Bleek, Henning Schwentner, Heinz Züllighoven (ed.): Software Engineering 2007 - Beiträge zu den Workshops, Bonn: 2007
URL: http://subs.emis.de/LNI/Proceedings/Proceedings106/gi-proc-106-007.pdf
BibTeX: Download - , , , :
Automatische, modellbasierte Testdatengenerierung durch Einsatz evolutionärer Verfahren
Informatik 2007 - 37. Jahrestagung der Gesellschaft für Informatik e.V. (GI) (Bremen, 24.09.2007 - 27.09.2007)
In: Rainer Koschke, Otthein Herzog, Karl H Rödiger, Marc Ronthaler (ed.): Informatik 2007 - Informatik trifft Logistik, Bonn: 2007
URL: http://cs.emis.de/LNI/Proceedings/Proceedings110/gi-proc-110-067.pdf
BibTeX: Download - , (ed.):
Computer Safety, Reliability, and Security
Berlin Heidelberg: 2007
(Lecture Notes in Computer Science, Vol. 4680)
ISBN: 978-3-540-75100-7
DOI: 10.1007/978-3-540-75101-4
URL: http://link.springer.com/content/pdf/10.1007%2F978-3-540-75101-4.pdf
BibTeX: Download - , , :
Interface Coverage Criteria Supporting Model-Based Integration Testing
20th International Conference on Architecture of Computing Systems (ARCS 2007) (Zürich, 12.03.2007 - 15.03.2007)
In: Marco Platzner, Karl E Grosspietsch, Christian Hochberger, Andreas Koch (ed.): Proceedings of the 20th International Conference on Architecture of Computing Systems (ARCS 2007), Zürich: 2007
BibTeX: Download
2006
- , :
Automatic Test Data Generation by Multi-Objective Optimisation
25th International Conference on Computer Safety, Reliability and Security (SAFECOMP 2006) (Gdansk, 26.09.2006 - 29.09.2006)
In: Janusz Górski (ed.): Computer Safety, Reliability, and Security, Berlin Heidelberg: 2006
DOI: 10.1007/11875567_32
URL: http://link.springer.com/content/pdf/10.1007%2F11875567.pdf
BibTeX: Download
2005
- :
Automated Generation and Evaluation of Dataflow-Based Test Data for Object-Oriented Software
Second International Workshop on Software Quality (SOQUA 2005) (Erfurt, 20.09.2005 - 22.09.2005)
In: Ralf Reussner, Johannes Mayer, Judith A. Stafford, Sven Overhage, Steffen Becker, Patrick J. Schroeder (ed.): Quality of Software Architectures and Software Quality: First International Conference on the Quality of Software Architectures, QoSA 2005, and Second International Workshop on Software Quality, SOQUA 2005, Berlin Heidelberg: 2005
DOI: 10.1007/11558569_16
URL: http://link.springer.com/content/pdf/10.1007%2F11558569.pdf
BibTeX: Download
2004
- :
Automatische Generierung optimaler datenflussorientierter Testdaten mittels evolutionärer Verfahren
21. Treffen der Fachgruppe TAV [Test, Analyse und Verifikation von Software] (Berlin, 17.06.2004 - 18.06.2004)
In: Udo Kelter (ed.): Softwaretechnik-Trends 2004
URL: http://pi.informatik.uni-siegen.de/stt/24_3/01_Fachgruppenberichte/TAV/TAV21P4Oster.pdf
BibTeX: Download - , :
A Data Flow Approach to Testing Object-Oriented Java-Programs
Probabilistic Safety Assessment and Management (PSAM7 - ESREL'04) (Berlin, 14.06.2004 - 18.06.2004)
In: Cornelia Spitzer, Ulrich Schmocker, Vinh N. Dang (ed.): Probabilistic Safety Assessment and Managment, London: 2004
DOI: 10.1007/978-0-85729-410-4_180
URL: http://link.springer.com/chapter/10.1007%2F978-0-85729-410-4_180
BibTeX: Download
2002
- , , :
A Hybrid Genetic Algorithm for School Timetabling
AI2002 15th Australian Joint Conference on Artificial Intelligence (Canberra, 02.12.2002 - 06.12.2002)
In: Mc Kay B., Slaney J. (ed.): AI 2002: Advances in Artificial Intelligence - 15th Australian Joint Conference on Artificial Intelligence, Berlin Heidelberg: 2002
DOI: 10.1007/3-540-36187-1_40
URL: http://www2.informatik.uni-erlangen.de/publication/download/AI02.ps.gz
BibTeX: Download
2001
- :
Implementierung eines evolutionären Verfahrens zur Risikoabschätzung (Diploma thesis, 2001)
BibTeX: Download - :
Stundenplanerstellung für Schulen mit Evolutionären Verfahren (Mid-study thesis, 2001)
BibTeX: Download
Committee work
| 2010-2019 | embedded world Conference, PC-Member, Session-Chair |
| 2016-2019 | MINTerAKTIV/GIFzuMINTS, Project Coordinator |
| 2015 | Software Engineering 2015 (SE2015), PC-Member |
| 2012-2014 | WEMUCS – Methods and tools for iterative development and optimization of software for embedded multicore systems, Project Coordinator |
| 2012/2013 | Member of Berufungskommission W2-Professorship Didaktik der Informatik (Successor Brinda) |
| 2006-2008 | UnITeD – Unterstützung Inkrementeller TestDaten, Project Coordinator |
| 2007 | International Conference on Computer Safety, Reliability and Security (SAFECOMP 2007), Member of the Organizing Committee |
Supervised theses
DOTgEAr
Brief description:
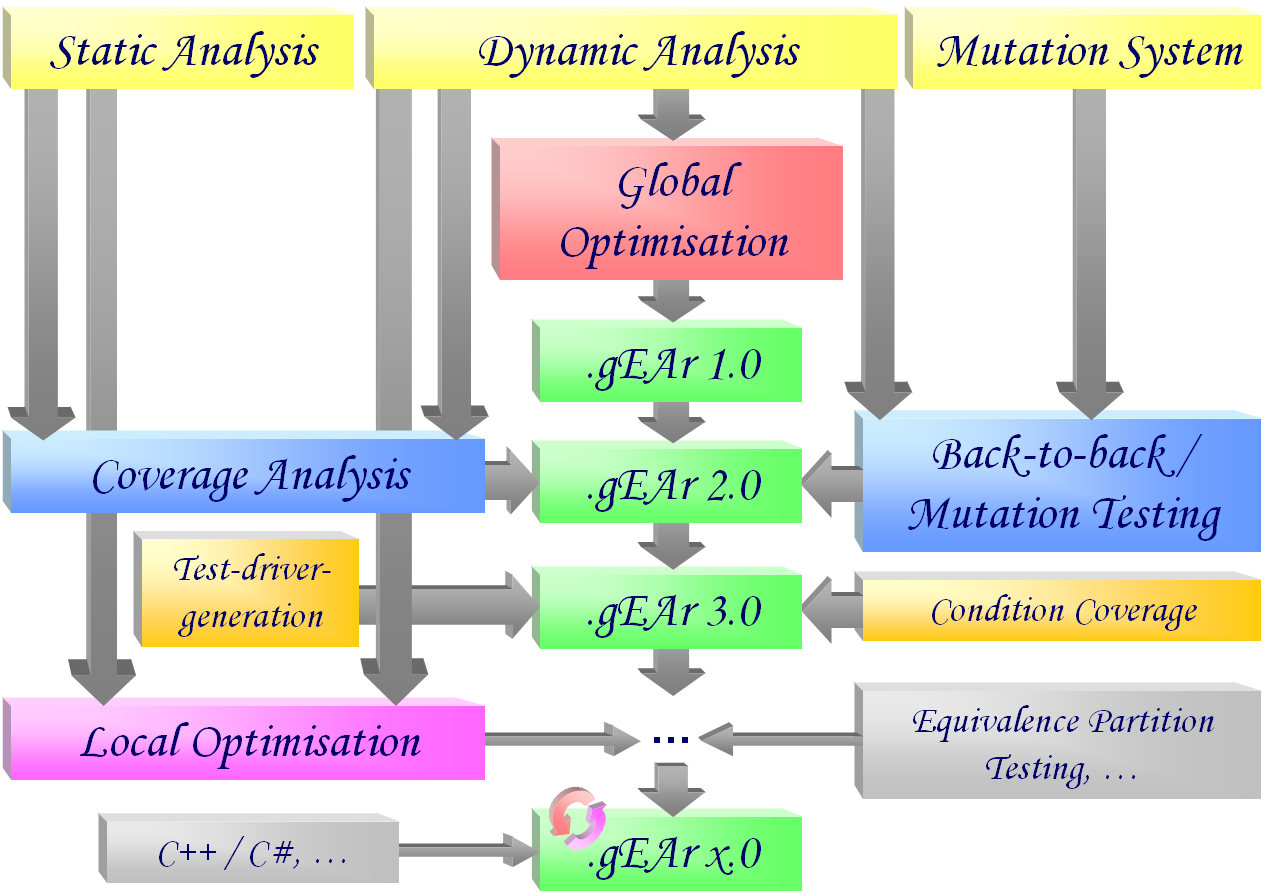
In spite of remarkably improved methods in software development, the increasing complexity of modern software systems still represents a main hindrance towards fault-free software development. Size and budget of today’s projects mostly forbid a complete formal verification, which in turn covers only the logical domain of the code but not the real environment, even in cases where verification is feasible. On this account, testing is still considered to be an important means of quality assurance previous to the final release. In order to increase the chances of revealing faults during the testing phase, test cases are selected according to different strategies: for functional testing, inputs are derived from the specified requirements, whilst for structural testing the code has to be executed as exhaustively as possible. In consequence of the complexity of the control structures, the identification of test data allowing to achieve high dataflow coverage is exceedingly time consuming. Checking the correctness of the test results has usually to be carried out by hand and therefore requires a high amount of effort. Therefore, the overall number of test cases is crucial, even if their generation can be performed at low cost, e. g. by means of a random generator.The aim of the ongoing research project is to automate the generation of adequate sets of dataflow-oriented test cases and to evaluate the adequacy of different techniques with respect to both quality achieved and effort required. In various application areas evolutionary algorithms have revealed as providing suitable search and optimisation strategies. Previous related investigations based on genetic algorithms were restricted to simple control flow criteria (statement and branch coverage), to special purpose programming languages or to language subsets hardly transferable to real projects.
Milestones achieved
- Dynamic analysis of the test execution
In order to identify the definition/use-pairs actually covered during the execution of a test case, a tool for monitoring the dynamic execution of a program was developed. It is intended to instrument the test object in such a manner that all relevant dataflow information is logged during each test run. The results were published on the occasion of the international conference PSAM7/ESREL’04. - Global optimization of test data sets
Based on the dynamic assessment of the coverage achieved by a test set, a procedure was developed aiming at generating an optimal set of test cases using evolutionary algorithms. The fitness function for evaluating each test set depends both on the number of covered dataflow pairs (see dynamic analysis) and on the size of the test set. For this reason the task is considered as a global optimisation problem independent from the control flow structure of the test object. For the actual generation of the test data, different genetic operators were developed to be used in parallel in the context of adaptive evolutionary algorithms. The different options were implemented in a toolset and tested and evaluated. Details have been published by the GI technical group TAV. - Static analysis of the test object
The evaluation of the results determined by the evolutionary algorithm requires the knowledge of both the coverage actually achieved (see dynamic analysis) and the coverage attainable. For this purpose a static analyzer has to locate the respective definitions and uses of each variable in the data flow graph. Together with the results achieved by the dynamic analysis, the static analysis is meant to improve the stopping criterion for the global optimisation. - Evaluation of the defect detection capability of the automatically generated test cases
In addition to evaluating the relative quality of a test set in terms of coverage (see static analysis), this project also aimed to estimate the quality of automatically generated test cases by considering their fault detection capability. For this purpose, a back-to-back test procedure based on the principle of mutation testing was implemented. Representative errors are injected into the original program and the behavior of the modified version during the execution of the generated test cases is compared with that of the unmodified version. The proportion of corrupted programs for which a deviation in behavior could be uncovered is an indicator of the fault detection capability of the test set. The results of the last two subtasks were published on the occasion of the international conference SOQUA 2005. - Extension of the approach to further testing strategies
The developed method for multi-objective generation and optimization of test cases can also be applied to other testing strategies. If coverage criteria are chosen which are orthogonal to the considered data flow oriented strategies, the detection of other types of defects can be expected. For example, in one subproject an approach for static analysis of the test object and dynamic analysis of the test execution with respect to the condition coverage criterion was developed and implemented. In another subproject, support for the structural equivalence class and boundary testing criterion was implemented, which, in combination with the existing criteria, is expected to result in an additional increase in the defect detection rate. - Addition of automatic test driver generators
Since specialized test drivers are required for the automatic generation of test cases, which are only suitable to a limited extent for the manual verification of test results, a two-stage automatic test driver generation was also implemented as part of a subproject. It first creates parameterizable test drivers, which are used solely during the test case optimization pahse, and then translates them into the usual jUnit syntax as soon as the generated and optimized test data is available. - Experimental evaluation of the developed tool
The practical relevance of the developed method was tested and evaluated in various experimental deployments. Java packages with up to 27 classes (5439 lines of code) served as test objects. The concurrent test execution during the generation and optimization of the test cases was parallelized on up to 58 networked computers. The results were published on the occasion of the international conference SAFECOMP 2006.
Planned milestones
- Extension of the automatic generation
In addition to the already supported testing criteria from the family of control and data flow strategies, the method and the implemented tool will be extended to other test procedures. Based on the already developed methods and tools, it is to be investigated how the above research results can be extended and improved using domain-specific knowledge in order to make the heuristics faster and more efficient – for example using distributed evolutionary methods. - Porting the tool to support other programming languages
Having already successfully implemented the automatic generation of test drivers and the generation and optimization of test data for Java programs, the broader applicability of the tool in industrial settings can be achieved by offering support for additional programming languages. This includes, in particular, the C language family widely used in the embedded domain – including the more recent derivatives C++ and C#. Building on the previous findings for Java, the existing tool will be extended to include static and dynamic analysis for C# programs. - Generation of additionally required test data by means of local optimization
Based on the identification of all data flow pairs (see static analysis), additional but yet missed control flow paths required for the fulfillment of the testing criterion can be determined. Corresponding test cases can be generated by applying evolutionary methods in a local optimization. For this purpose, a new fitness function is defined based on graph-theoretic properties of the control flow graph. The already implemented instrumentation (dynamic analysis) of the test object will be extended suitably. Thus, the automatic generation of test cases is locally directed in a more targeted way and further improved with respect to time and achieved data flow coverage.
- Download: Dissertation (PDF)