
Norbert Oster
Dr.-Ing. Norbert Oster, Akad. ORat

Department Informatik (INF)
Lehrstuhl für Informatik 2 (Programmiersysteme)
Martensstr. 3
91058 Erlangen
- Telefon: +49 9131 85-28995
- Faxnummer: +49 9131 85-28809
- E-Mail: norbert.oster@fau.de
- Webseite: https://www.ps.tf.fau.de/person/oster
Sprechstunde
n.V. per E-Mail-
Verifikation und Validierung in der industriellen Praxis
(Projekt aus Eigenmitteln)
Laufzeit: seit 01.01.2022Erkennung von Flaky-Tests auf Basis von Software-Versionsdaten und Testausführungshistorie
Regressionstests werden häufig und aufgrund ihres großen Umfangs zumeist vollautomatisiert ausgeführt. Sie sollen sicherstellen, dass Änderungen an einzelnen Komponenten eines Softwaresystems keine unerwünschten Nebenwirkungen auf das Verhalten von Teilsystemen haben, die von den Modifikationen eigentlich gar nicht betroffen sein sollten. Doch selbst wenn ein Testfall ausschließlich unveränderten Code ausführt, kann es trotzdem vorkommen, dass er manchmal erfolgreich ist und manchmal fehlschlägt. Derartige Tests nennt man "flaky" und die Gründe dafür können sehr vielfältig sein, u.a. Wettlaufsituationen bei nebenläufiger Ausführung oder vorübergehend nicht verfügbare Ressourcen (z.B. Netzwerk oder Datenbanken). Flaky-Tests sind für den Testprozess in jeder Hinsicht ein Ärgernis, denn sie verlangsamen oder unterbrechen sogar die gesamte Testausführung und sie untergraben das Vertrauen in die Testergebnisse: Ist ein Testlauf erfolgreich, kann daraus nicht zwangsläufig geschlossen werden, dass das Programm diesbezüglich wirklich fehlerfrei ist, und schlägt der Test fehl, müssen ggf. teure Ressourcen investiert werden, um das Problem zu reproduzieren und ggf. zu beheben.
Der einfachste Weg, Test-Flakyness zu erkennen, besteht darin, Testfälle wiederholt auf der identischen Code-Basis auszuführen, bis sich das Testergebnis ändert oder mit einer gewissen statistischen Aussagesicherheit davon auszugehen ist, dass der Test nicht "flaky" ist. Im industriellen Umfeld ist dieses Vorgehen jedoch selten möglich, da Integrations- oder Systemtests extrem zeit- und ressourcenaufwendig sein können, z.B. weil sie die Verfügbarkeit spezieller Test-Hardware voraussetzen. Aus diesem Grund ist es wünschenswert, die Klassifikation von Testfällen hinsichtlich Flakyness ohne wiederholte Neuausführung vorzunehmen, sondern dabei ausschließlich auf die bereits verfügbaren Informationen aus den bisherigen Entwicklungs- und Testphasen zurückzugreifen.
Im Jahr 2022 wurden verschiedene sogenannte Black-Box-Verfahren zur Erkennung von Test-Flakyness vergleichend untersucht, in einem realen industriellen Testprozess mit 200 Testfällen evaluiert und in ein praktisches Werkzeug implementiert. Die Klassifikation eines Testfalls erfolgt dabei ausschließlich auf Basis allgemein verfügbarer Informationen aus Versionskontrollsystemen und Testausführungswerkzeugen - also insbesondere ohne aufwändige Analyse der Codebasis oder Überwachung der Testüberdeckung, die im Falle eingebetteter Systeme in den meisten Fällen ohnehin unmöglich wäre. Von den 122 verfügbaren Indikatoren (u.a. z.B. die Testausführungszeit, die Anzahl der Code-Zeilen oder die Anzahl der geänderten Code-Zeilen in den letzten 3, 14 und 54 Tagen) wurden verschiedene Teilmengen extrahiert und ihre Eignung für die Erkennung von Test-Flakyness bei Verwendung unterschiedlicher Verfahren untersucht. Zu diesen Verfahren zählen regelbasierte Methoden (z.B. "ein Test ist flaky, wenn er mind. fünfmal innerhalb des Beobachtungsfensters fehlgeschlagen ist, aber dabei nicht fünfmal hintereinander"), empirische Bewertungen (u.a. die Bestimmung der kumulierten gewichteten "flip rate", also die Häufigkeit des Alternierens zwischen Testerfolg und -fehlschlag) sowie verschiedene Verfahren aus der Domäne des Maschinellen Lernens (u.a. Klassifikationsbäume, Random Forest oder Multi-Layer Perceptrons). Die Verwendung KI-basierter Klassifikatoren zusammen mit dem SHAP-Ansatz zur Erklärbarkeit von KI-Modellen führte zur Bestimmung der wichtigsten vier Indikatoren ("features") für die Bestimmung der Test-Flakyness im konkret untersuchten industriellen Umfeld. Als optimal hat sich dabei das sog. "Gradient Boosting" mit der kompletten Indikatorenmenge herausgestellt (F1-score von 96,5%). Nur marginal niedrigere Accuracy- und Recall-Kennwerte (bei nahezu gleichem F1-score) konnte das gleiche Verfahren mit nur vier ausgewählten Features erzielen.
Synergien von vor- und nachgelagerten Analysemethoden zur Erklärung künstlicher Intelligenz
Der Einsatz künstlicher Intelligenz verbreitet sich rasant und erobert immer neue Domänen des täglichen Lebens. Nicht selten treffen Maschinen dabei auch durchaus kritische Entscheidungen: Bremsen oder Ausweichen beim autonomen Fahren, Kredit(un)würdigkeit privater Personen bzw. von Unternehmen, Diagnose von Krankheiten aus diversen Untersuchungsergebnissen (z.B. Krebserkennung aus CT/MRT-Scans) u.v.m. Damit ein solches System im produktiven Einsatz Vertrauen verdient, muss sichergestellt und nachgewiesen sein, dass die gelernten Entscheidungsregeln korrekt sind und die Realität widerspiegeln. Das Trainieren eines maschinellen Modells selbst ist ein sehr ressourcenintensiver Prozess und die Güte des Ergebnisses ist in der Regel nur mit extrem hohem Aufwand und fundiertem Fachwissen nachträglich quantifizierbar. Der Erfolg und die Qualität des erlernten Modells hängt nicht nur von der Wahl des KI-Verfahrens ab, sondern wird im besonderen Maße vom Umfang und der Güte der Trainingsdaten beeinflusst.
Im Jahr 2022 wurde daher untersucht, welche qualitativen und quantitativen Eigenschaften eine Eingabemenge haben muss ("a-priori-Bewertung"), um damit ein gutes KI-Modell zu erzielen ("a-posteriori-Bewertung"). Dazu wurden verschiedene Bewertungskriterien aus der Literatur vergleichend bewertet und darauf aufbauend vier Basisindikatoren definiert: Repräsentativität, Redundanzfreiheit, Vollständigkeit und Korrektheit. Die zugehörigen Metriken erlauben eine quantitative Bewertung der Trainingsdaten im Vorfeld. Um die Auswirkung schlechter Trainingsdaten auf ein KI-Modell zu untersuchen, wurde mit dem sog. "dSprites"-Datensatz experimentiert, einem verbreiteten Generator für Bilddateien, der bei der Bewertung von Bilderkennungsverfahren eingesetzt wird. Damit wurden gezielt verschiedene Trainingsdatensätze generiert, die sich jeweils in genau einem der vier Basisindikatoren unterscheiden und dabei quantitativ unterschiedliche "a-priori-Güte" haben. Damit wurden jeweils zwei verschiedene KI-Modelle trainiert: Random Forest und Convolutional Neural Networks. Anschließend wurde die Güte der Klassifikation durch das jeweilige Modell anhand der üblichen statistischen Maße (Accuracy, Precision, Recall, F1-score) quantitativ bewertet. Zusätzlich wurde SHAP (ein Verfahren zur Erklärbarkeit von KI-Modellen) genutzt, um die Gründe für eine etwaige Missklassifikation bei schlechter Datenlage zu ermitteln. Wie erwartet, korreliert die Modellqualität mit der Trainigsdatenqualität: Je besser letztere hinsichtlich der vier Basisindikatoren abschneiden, desto genauer klassifiziert das trainierte Modell unbekannte Daten. Eine Besonderheit hat sich jedoch bei der Redundanzfreiheit herausgestellt: Erfolgt die Bewertung eines trainierten Modells mit komplett neuen/unbekannten Eingaben, dann ist die Genauigkeit der Klassifikation teils signifikant schlechter, als wenn die verfügbaren Eingabedaten in einen Trainings- und einen Evaluationsdatensatz geteilt werden: In letzteren Fall suggeriert die a-posteriori-Bewertung irreführend eine höhere Modellqualität.
Few-Shot Out-Of-Domain-Erkennung in der maschinellen Verarbeitung natürlicher Sprache
Die maschinelle Verarbeitung natürlicher Sprache ("Natural Language Processing", kurz NLP) hat viele Anwendungsgebiete, z.B. telefonische oder schriftliche Dialogsystemen (sog. Chat-Bots), die eine Kino-Auskunft erteilen, eine Eintrittskarte buchen, eine Krankmeldung aufnehmen oder Antworten auf diverse Fragen in bestimmten industriellen Abläufen geben. Häufig beteiligen sich derartige Chat-Bots auch in sozialen Medien, um z.B. kritische Äußerungen zu erkennen und ggf. zu moderieren. Mit zunehmendem Fortschritt auf dem Gebiet der künstlichen Intelligenz im Allgemeinen und der NLP im Speziellen, verbreiten sich zunehmend selbstlernende Modelle, die ihr fachliches und sprachliches Wissen erst während des konkreten praktischen Einsatzes dynamisch (und daher meist unüberwacht) ergänzen. Doch derartige Ansätze sind empfänglich für absichtlich oder unabsichtlich bösartige Beeinflussung. Beispiele aus der industriellen Praxis haben gezeigt, dass Chat-Bots schnell z.B. rassistische Äußerungen in sozialen Netzen "erlernen" und anschließend gefährdende extremistische Äußerungen tätigen. Daher ist es von zentraler Bedeutung, dass NLP-basierte Modelle zwischen gültigen "In-Domain (ID)" und ungültigen "Out-Of-Domain (OOD)" Daten (also sowohl Ein- als auch Ausgaben) unterscheiden können. Dazu benötigen die Entwickler eines NLP-Systems für das initiale Training des KI-Modells jedoch eine immense Menge an ID- und OOD-Trainingsdaten. Während erstere schon schwer in hinreichender Menge zu finden sind, ist die a-priori-Wahl der letzteren i.d.R. kaum sinnvoll möglich.
Im Jahr 2022 wurden daher verschiedene Ansätze zur OOD-Erkennung untersucht und vergleichend bewertet, die mit wenigen bis keinen ("few-shot") Trainingsdaten funktionieren. Als Grundlage für die experimentelle Evaluierung diente das derzeit beste und am weitesten verbreitete, Transformer-basierte und vortrainierte Sprachmodell RoBERTa. Zur Verbesserung der OOD-Erkennung wurden u.a. "fine-tuning" eingesetzt und untersucht, wie zuverlässig die Anpassung eines vortrainierten Modells an eine konkrete Domäne funktioniert. Zusätzlich wurden verschiedene Scoring-Verfahren implementiert und evaluiert, um Grenzwerte für die Klassifikation von ID- und OOD-Daten zu bestimmen. Um das Problem der fehlenden Trainingsdaten zu lösen, wurde auch ein Verfahren namens "data augmentation" evaluiert: Dabei wurden mittels GPT3 ("Generative Pretrained Transformer 3", ein autoregressives Sprachmodell, das Deep Learning verwendet, um menschenähnlichen Text zu erzeugen) zusätzliche ID- und OOD-Daten für das Training bzw. die Evaluation von NLP-Modellen generiert.
Anwendung gewichteter Kombinatorik bei der Erzeugung und Auswahl von Parametern und deren Repräsentanten im Software-Test
Einige funktionale Testverfahren (sogenannte Black-Box-Tests), beispielsweise die Äquivalenzklassenmethode oder Grenzwertanalyse, fokussieren sich auf einzelne Parameter. Für diese Parameter ermitteln sie Repräsentanten (Werte oder Klassen von Werten), die im Test zu berücksichtigen sind. Da für die Durchführung von Tests in der Regel nicht nur ein einzelner Parameter, sondern mehrere Parameter benötigt werden, müssen zur Ausführung eines Tests Repräsentanten mehrerer Parameter miteinander kombiniert werden. Üblicherweise werden dazu gut verstandene Kombinationsmethoden verwendet, wie "All Combinations", "Pair-wise" oder "Each choice". Dabei werden Informationen über Gewichte (Attribute wie bspw. die Wichtigkeit oder Priorität) der Parameter und Repräsentanten nicht berücksichtigt, die sich auf die Anzahl der zugehörigen Testfälle (z.B. aufgrund der Wichtigkeit) bzw. auf ihre empfohlene Reihenfolge (im Sinne der Priorisierung) auswirken sollten. Darüber hinaus gibt es im Falle der Äquivalenzklassenmethode Szenarien, bei denen eine Kombination mehrerer ungültiger Klassen in einem Testfall optional explizit gewünscht, gänzlich unerwünscht oder auf eine bestimmte Anzahl beschränkt bleiben sollte, um einerseits Fehlerkombinationen gezielt zu testen, aber andererseits die Fehlerlokalisierung zu vereinfachen. Es besteht Grund zur Annahme, dass durch die Berücksichtigung von derartigen Gewichten und Optionen zielgerichtetere und letztlich effizientere Testfälle abgeleitet werden können.
Im Jahr 2023 wurden daher zunächst bereits bekannte kombinatorische Ansätze untersucht und vergleichend bewertet, die Gewichte bei der Kombination von Parametern oder ihren Werten berücksichtigen. Darauf aufbauend wurde ein neuartiger Ansatz in der Erzeugung und Auswahl von Parametern und deren Repräsentanten im Software-Test entwickelt. Die vorgeschlagene Methode nutzt ein Gewichtungssystem, um individuelle Parameter, deren Äquivalenzklassen und konkrete Repräsentanten dieser Klassen in einer Testfallmenge zu priorisieren. Darüber hinaus können auch jeweils deren Interaktionen gezielt gewichtet werden, um bei Bedarf bestimmte Kombinationen häufiger in der generierten Testfallmenge vorkommen zu lassen. Zur Evaluation des Ansatzes wurde prototypisch eine geeignete Datenstruktur zur Repräsentation der verschiedenen Gewichtungen definiert. Anschließend wurden Bewertungsfunktionen für bestehende Testfallmengen implementiert, um quantitativ bestimmen zu können, wie gut eine Testfallmenge die vorgegebene Kombinatorik erfüllt. In einem weiteren Schritt wurden diese Bewertungsfunktionen in Kombination mit verschiedenen systematischen und heuristischen Verfahren verwendet (SAT-Solver Z3 bzw. Simulated Annealing und Genetische Algorithmen), um neue Testfallmengen passend zur Gewichtung zu generieren oder bestehende Testfallmengen durch Ergänzung fehlender Testfälle dahingehend zu optimieren. In den Versuchsreihen hat Simulated Annealing die schnellsten und besten Ergebnisse ermittelt. Das SAT-Verfahren funktionierte zwar für kleine Problemstellungen, war aber für größere Testfallmengen aufgrund exorbitanter Laufzeiten nicht mehr praxistauglich.
-
Informatik als Grundlage eines erfolgreichen MINT-Studiums entlang der Bildungskette fördern
(Drittmittelfinanzierte Einzelförderung)
Laufzeit: 01.11.2019 - 31.10.2022
Mittelgeber: Bayerisches Staatsministerium für Wissenschaft und Kunst (StMWK) (seit 2018)
URL: https://www.ddi.tf.fau.de/forschung/laufende-projekte/cs4mints-informatik-als-grundlage-eines-erfolgreichen-mint-studiums-entlanDie fortschreitende Digitalisierung verändert neben dem Arbeitsmarkt auch die Bildungslandschaft. Mit Mitteln aus dem DigitalPakt Schule werden u.a. im Zuge des Programms BAYERN DIGITAL II gravierende Veränderungen in der Informatikausbildung vorangetrieben, die wiederum neue Herausforderungen auf den verschiedenen Bildungsebenen mit sich ziehen.
Das Projekt CS4MINTS begegnet eben diesen Herausforderungen entlang der Bildungskette und knüpft an bereits im Rahmen des Projekts MINTerAKTIV gestartete Maßnahmen, wie u.a. der Stärkung der Begegnung zunehmender Heterogenität der Studierenden im Zuge der Einführungsveranstaltung in die Informatik, an.So wird im Zuge der Begabtenförderung das Frühstudium in Informatik aktiv für Mädchen beworben und das Angebot explizit erweitert. Durch frühzeitiges Vorgehen gegen genderspezifische Stereotypen bzgl. Informatik sowie eine Erweiterung des Fortbildungsangebots um gendersensitiven Informatikunterricht in allen Schularten, soll langfristig ein signifikanter Anstieg des Frauenanteils im Fach Informatik erreicht werden.
Durch die Erweiterung des Pflichtfachs Informatik in allen Schulen besteht außerdem ein großer Bedarf an geeigneten Unterrichtskonzepten und einer Stärkung der LehrerInnenbildung. Hierfür soll im Projektzeitraum ein regionales Netzwerk aufgebaut werden, um universitär erarbeitete und evaluierte Unterrichtsideen zur Stärkung von MINT im curricularen und extra-curricularen Rahmen zur Verfügung zu stellen.
Im Jahr 2020 haben wir mit der ersten Pilotierung der Konzeption zur Automatisierung des Feedbacks im Übungsbetrieb der Einführungsveranstaltung in die Informatik begonnen. Dazu wurden die Rückgabewerte der JUnit-Tests von Abgaben analysiert und erste mögliche Fehlerquellen untersucht. Im nächsten Schritt soll eine Möglichkeit ausgearbeitet werden, wie auf Grundlage dieser Rückgabewerte auf Programmierfehler oder Fehlvorstellungen der Studierenden geschlossen werden kann. Ziel dieser Bemühungen ist es schließlich, den Studierenden ein automatisch generiertes, kompetenzorientiertes Feedback zu ermöglichen, welches ihnen nach Abgabe der Programmieraufgaben (oder ggfls. schon während der Erarbeitungsphase) zur Verfügung steht. Das Feedback soll aufzeigen an welcher Stelle Fehler im Programmcode auftraten sowie auf mögliche Ursachen hinweisen.
Im Hinblick auf eine Begegnung von Heterogenität haben wir im Jahr 2020 die Inhalte des Repetitoriums für Informatik (RIP) dem bayerischen Lehrplan verschiedener Schularten gegenübergestellt. Die Inhalte sollen anschließend so angepasst werden, dass StudienanfängerInnen unterschiedlichster Bildungszweige gleiche Chancen haben, mittels des Repetitoriums mögliche Defizite zu erkennen und diese zu beheben. Außerdem wurde im Wintersemester 2020 während der Repetitoriumswoche erstmalig eine tägliche Programmiersprechstunde eingerichtet, in der es den TeilnehmerInnen möglich war Fragen zu stellen sowie Feedback zu den Aufgaben zu erhalten.
Der Einstieg in die Programmierung stellt für viele Studierende eine der großen Hürden zu Beginn des Studiums dar. Um den Programmieranfänger:innen zusätzliches Feedback zu ermöglichen, haben wir im Jahr 2021 das Projekt Feedback+ konzipiert und pilotiert. Im Rahmen von Feedback+ haben die Studierenden die Möglichkeit, Probleme, welche während der Bearbeitung der Übungsaufgaben oder beim Einrichten/Benutzen der Programmierumgebung auftreten, zu dokumentieren und in wöchentlich buchbaren Einzelsprechstunden zusätzliches Feedback zu erhalten. Dazu wurde eine StudOn-Umgebung eingerichtet, in der Probleme systematisch dokumentiert werden können. Eine erste Evaluation in Form von Einzelinterviews mit den teilnehmenden Studierenden lieferte ein durchweg positives Feedback und einen Wunsch auf Fortsetzung des Projektes.
-
Grundlagen der Informatik als Fundament eines zukunftsorientierten MINT-Studiums
(Drittmittelfinanzierte Einzelförderung)
Laufzeit: 01.10.2016 - 30.09.2019
Mittelgeber: Bayerisches Staatsministerium für Bildung und Kultus, Wissenschaft und Kunst (ab 10/2013)
URL: https://www2.cs.fau.de/research/GIFzuMINTS/Die zunehmende Digitalisierung aller Wissenschafts- und Lebensbereiche hat dazu geführt, dass Kompetenzen in den Grundlagen der Informatik für Studierende aller Studiengänge der Technischen Fakultät (und darüber hinaus) als essentiell erachtet werden. Für den Studienerfolg haben sich diese, typischerweise direkt in der Studieneingangsphase verorteten, Lehrveranstaltungen allerdings für viele Studierende als problematische Hürde erwiesen, die letztlich häufig zum Studienabbruch führen kann. Aus diesem Grund widmen wir uns dem Ausbau der Unterstützung von angehenden Studierenden beim Übergang Schule-Hochschule sowie während der Studieneingangsphase.
Die Projektschwerpunkte liegen hinsichtlich der Studienorientierung in der Förderung des potenziellen MINT-Nachwuchses bereits vor Studienbeginn durch regionale und überregionale Kontakte wie z.B. Unterstützung bei W-Seminaren oder Fortbildungen von Lehrerinnen und Lehrern als Multiplikatoren für die Studienwahl. Hinsichtlich des Übergangs Schule-Hochschule steht der Ausgleich unterschiedlicher Vorkenntnisse der Studienanfänger durch Repetitorien im Vordergrund. In der Studieneingangsphase liegt der Schwerpunkt in der Senkung der Abbruchquote in MINT-Studiengängen durch spezielle Intensivierungsübungen und Tutorenschulungen unter Berücksichtigung der Heterogenität.
2018 stand unter anderem die Untersuchung der Wirksamkeit aller Maßnahmen im Fokus. Untersucht wurde der Einfluss des angestiegenen Übungsgruppenangebots und der umfangreichen Unterstützung durch die Tutorinnen und Tutoren. Außerdem war die Wirksamkeitsuntersuchung hinsichtlich des Zusammenhangs von Wahrnehmung des Übungsangebots und Abbruchquote Untersuchungsgegenstand. Weiterhin wurden die Auswirkungen der Teilnahme am Repetitorium auf die Leistungen in den Übungen und in der Klausur untersucht.
Um das Ziel der Gewinnung und Qualifizierung von Lehrerinnen und Lehrern als Multiplikatoren zu erreichen, wurde das Angebot an Lehrerfortbildungen weiter ausgebaut. In diesen Fortbildungen wurden innovative Herangehensweisen, Beispiele und Inhalte für den Unterricht mit dem Ziel aufgezeigt, dass die Teilnehmerinnen und Teilnehmer das Gelernte an ihre Schülerinnen und Schüler weitervermitteln.
Ein weiteres Teilziel war die quantitative und qualitative Verbesserung der in Informatik geschriebenen W-Seminar-Arbeiten. Dazu wurde eine 24-seitige Broschüre entwickelt und an Schulen in umliegenden Landkreisen verschickt. Mit dieser Broschüre sollen Lehrkräfte bei der Gestaltung und Durchführung von W-Seminaren in der Informatik mit Themenvorschlägen, Hinweisen und einer Checkliste für die Schülerinnen und Schüler unterstützt werden. Im Jahr 2019 endete das Projekt GIFzuMINTS mit einem besonderen Höhepunkt: Am 20.05.2019 besuchte uns der bayerische Staatsminister für Wissenschaft und Kunst, Bernd Sibler, zusammen mit dem stellvertretenden Hauptgeschäftsführer der vbw bayme vbm, Dr. Christof Prechtl, um sich über den Stand des Projekts zu informieren. Wissenschaftsminister Bernd Sibler zeigte sich beim Projektbesuch beeindruckt: "Das Konzept der FAU geht passgenau auf die Anforderungen eines Informatikstudiums ein. Die jungen Studentinnen und Studenten werden dort abgeholt, wo sie stehen. Das ist exakt unser Anliegen, das wir mit MINTerAKTIV verfolgen: Wir wollen, dass jede Studentin und jeder Student die Unterstützung bekommt, die sie bzw. er braucht, um das Studium erfolgreich abschließen zu können."Bis zum Projektende wurden die entwickelten und umgesetzten Maßnahmen gründlich evaluiert und als dauerhafte Angebote etabliert. Dabei wurde das Repetitorium Informatik in ein kontinuierliches virtuelles Angebot zum Selbststudium überführt und auf den neuesten Stand der Technik aktualisiert. Das an besonders begabte Studierende gerichtete Angebot der Vorbereitung auf die Teilnahme an internationalen Programmierwettbewerben wurde ausgeweitet und als Vertiefungsmodul eingerichtet. Damit die begonnenen Maßnahmen auch zukünftig reibungslos weitergeführt werden können, wurde bereits frühzeitig die Aufnahme in das anschließende Förderprojekt beantragt, das zukünftig als CS4MINTS auch bewilligt wurde. -
Methoden und Werkzeuge zur iterativen Entwicklung und Optimierung von Software für eingebettete Multicore-Systeme
(Drittmittelfinanzierte Einzelförderung)
Laufzeit: 15.10.2012 - 30.11.2014
Mittelgeber: Bayerisches Staatsministerium für Wirtschaft, Infrastruktur, Verkehr und Technologie (StMWIVT) (bis 09/2013)Für eingebettete Systeme werden Multicore-Prozessoren immer wichtiger, da diese hohe Rechenleistung bei niedrigem Energieverbrauch ermöglichen. Die Entwicklung von paralleler Software für diese Systeme stellt jedoch neue Herausforderungen für viele Branchen dar, da existierende Software und Werkzeuge nicht für Parallelität entworfen wurden. Die effiziente Entwicklung, die Optimierung und das Testen von Multicore-Software, speziell für eingebettete Systeme mit hohen Zuverlässigkeits- und Zeitanforderungen, sind offene Probleme.
Im Verbundprojekt "WEMUCS" [http://www.multicore-tools.de/] wurden im 2-jährigen Verlauf des Projekts Techniken für die effiziente und iterative Entwicklung, die Optimierung sowie den Test von Multicore-Software durch neue Werkzeuge und Methoden geschaffen. Hierfür wurden mehrere Technologien und innovative Werkzeuge zur Modellierung, Simulation, Visualisierung, Tracing und zum Test entwickelt und zu einer Werkzeugkette integriert. Diese wurden in Fallstudien in der Automobilbranche, der Telekommunikation und der Automatisierungstechnik evaluiert und iterativ weiter entwickelt.
Während es für klassische Single-Core-Applikationen gut erforschte Methoden zur Erzeugung von Testfällen und bewährte Maße und Hierarchien für deren Überdeckung gibt, sind ebenfalls nötige Methoden für mehrkernfähige Anwendungen noch nicht etabliert. Gerade durch das Zusammenspiel gleichzeitig ablaufender Aktivitäten können sich aber erst Fehlerzustände ergeben, die durch das isolierte Testen jeder einzelnen, beteiligten Aktivität nicht identifiziert werden können. Als Teil des WEMUCS-Projektes (genauer: Arbeitspaket AP3 [http://www.multicore-tools.de/de/test.html]) haben wir ausgehend von einem Fallbeispiel ein generalisierbares Verfahren entwickelt (im Folgenden "Testing-Pipeline" genannt), um derartige Wechselwirkungen von parallelen Aktivitäten systematisch zu lokalisieren und etwaige Auswirkungen auf den Programmablauf durch Testmethoden gezielt zu untersuchen.
Zum Zweck der praktischen Erprobung der im AP3 entwickelten Testing-Pipeline, einschließlich der automatischen Parallelisierung von bislang sequentiellem Code, wurde vom Projektpartner Siemens eine Gepäckförderanlage, wie man sie von Flughäfen kennt, vollständig (inkl. Code) modelliert. Das modellierte Fallbeispiel ist so gestaltet, dass man unterschiedlich große Anlagen, d.h. u.a. mit unterschiedlich vielen Förderbändern für Zufuhr bzw. Abtransport, automatisiert generieren kann. Die Hardware der Förderanlage wird dabei durch das Simulationsgerät SIMIT von Siemens emuliert, während die Steuerungssoftware (in der Sprache: AWL) auf einer Software-basierten SPS ausgeführt wird.
Im ersten Schritt der Testing-Pipeline wird der AWL-Code durch ein vom Lehrstuhl für Programmiersysteme im Berichtszeitraum und im Vorjahr entwickeltes Werkzeug in die für Menschen verständlichere Programmiersprache HLL konvertiert und die in AWL noch sequentiell ausgeführte Abschnitte in einem direkt angeschlossenen zweiten Schritt automatisch in parallel ausgeführte HLL-Einheiten überführt. Für eine exemplarische Gepäckförderanlage mit acht Zufuhr- und acht Abtransportförderbändern sowie einem ringförmigen Zwischenband aus mehreren geraden und gewundenen Segmenten hat unser Werkzeug 11.704 Zeilen sequentiellen AWL-Code automatisch in 34 KB parallelen HLL-Code transcodiert.
Im dritten Schritt der Testing-Pipeline wird der HLL-Code analysiert und durch ein weiteres, im Projektverlauf vom Lehrstuhl entwickeltes Werkzeug in ein Testmodell überführt. Dieses Testmodell stellt den interprozeduralen Kontrollfluss der nebenläufigen Unterprogramme zusammen mit potentiellen und für den Test relevanten Thread-Wechseln als hierarchische UML-Aktivitäten dar (derzeit als XMI-Dokument, z.B. für den Import in Enterprise Architect von Sparx Systems). Für die vorangehend beschriebene Gepäckförderanlage hat unser Werkzeug ebenfalls automatisch 103 Aktivitätsdiagramme (mit 1.302 Knoten und 2.581 Kanten) erzeugt.
Nach einem optionalen Schritt, bei dem das Testmodell von einem Tester manuell angepasst werden kann (z.B. um Prioritäten zu ändern oder zusätzliche Prüfschritte einzubauen), kann das Modell dann in die MBTsuite des Projektpartners sepp.med GmbH geladen werden. Dieses umfangreich konfigurierbare Werkzeug dient zur Generierung von Testfällen, die eine möglichst vollständige Überdeckung des Modells anstreben. Für die exemplarische Gepäckförderanlage wurde u.a. auf einem haushaltsüblichen Standard-PC innerhalb von lediglich sechs Minuten eine hochgradig optimierte Testfallmenge generiert, die mit nur 10 Testfällen rund 99% der Knoten und 78% der Kanten im Gesamtmodell überdecken konnte.
Zusammen mit dem Projektpartner sepp.med GmbH demonstrieren wir im Projekt dass und wie zwei Export-Module für die MBTsuite entwickelt werden können, die die generierten Testfälle einerseits für den menschlichen Tester als Tabellendokument ausgibt, bei dem jeder Testfall ein Tabellenblatt füllt, dessen Spalten und Zeilen anschaulich den nebenläufigen Ablauf und die Thread-Wechsel zeigen, sowie andererseits zur weiteren Verarbeitung als ausführbare Testfallmenge (d.h. hier als Java-Programm für den nun folgenden Schritt). Die ausführbaren Tests bestehen aus mehreren Testfällen, bei dem jeder Testfall aus mehreren Testschritten und jeder Testschritt aus Steueranweisungen besteht, so dass ein Testlauf einer jederzeit eindeutig reproduzierbaren Programmausführung des zu testenden, nebenläufigen HLL-Codes entspricht. Werden diese Testfälle gestartet, dann schließt sich die Werkzeugkette, indem der HLL-Code in einem von Lehrstuhl entwickelten HLL-Emulator nach der Vorgabe im Testfall kontrolliert ausgeführt und dabei gleichzeitig ein detailliertes Protokoll der Testausführung zum Zweck der Visualisierung generiert wird.
Dieses Protokoll kann schließlich durch ein von der sepp.med GmbH entwickeltes Plug-In für Enterprise Architect wie eine zusätzliche Schicht/Ansicht "über" das Testmodell gelegt werden, so dass der Tester für jeden einzelnen Testfall bzw. für die gesamte Testfallmenge graphisch nachvollziehen kann, welche Abläufe getestet wurden und wo gegebenenfalls ein Fehler aufgetreten ist: Die "graphische Spur" endet in diesem Fall genau an der betroffenen HLL-Anweisung und lässt sich z.B. "rückwärts" untersuchen, um die Ursache des Fehlschlags zu identifizieren.
Das am Fallbeispiel prototypisch realisierte Verfahren stellt damit einen wesentlichen Beitrag zum Testen nebenläufigen Codes auf eingebetteten Systemen dar. Es ist ein Beitrag des Lehrstuhls Informatik 2 zum "IZ ESI" [http://www.esi.uni-erlangen.de].
-
Inter-Thread Testing
(Projekt aus Eigenmitteln)
Laufzeit: 01.01.2012 - 31.12.2013Zur Beschleunigung von Rechensystemen setzen Prozessor-Hersteller schon lange nicht mehr auf steigende Taktraten - im Gegenteil: Die absolute Taktzahl sinkt, stattdessen werden in Prozessoren immer mehr unabhängige Recheneinheiten (cores) verbaut. Dafür müssen die Entwickler nun umdenken: Sie bekommen ihre Applikationen nur dann performanter (effizienter), wenn sie ihre Programme so modularisieren, dass unabhängige Codeabschnitte nebenläufig ausgeführt werden. Leider sind heutige Systeme schon funktional so komplex geworden, dass selbst die Entwicklung für eine sequentielle Ausführung noch nicht fehlerfrei gelingt - die Parallelisierung auf mehrere Rechenkerne fügt der System-Konzeption eine weitere nicht-funktionale Komplexitätsdimension hinzu. Zwar hat die Forschung auf dem Gebiet der Softwaretechnik eine Vielzahl von Qualitätssicherungsmaßnahmen hervorgebracht, da aber die zunehmende Verbreitung von Mehrkernsystemen noch verhältnismäßig neu ist, fehlen bislang wirksame Verfahren zum Testen nebenläufiger Applikationen.
Das vorliegende Projekt hat zum Ziel, diese Lücke durch Bereitstellung eines automatisierten Testsystems zu schließen. Dazu bedarf es zunächst einer Testkriterienhierarchie, die Überdeckungsmaße speziell für das Konzept der Nebenläufigkeit bereitstellt. Vergleichbar z.B. der Verzweigungsüberdeckung für sequentielle Programme, die die Ausführung jedes Programmzweigs im Test fordert (z.B. die Bedingung eines if-statements sowohl wahr als auch falsch erzwingt - auch dann, wenn es keinen expliziten else-Zweig gibt), muss ein fundiertes Testendekriterium für nebenläufige Applikationen die systematische Ausführung aller relevanten Verschränkungen fordern (z.B. alle Reihenfolge-Kombinationen die auftreten können, wenn zwei Fäden einen gemeinsamen Speicherbereich verändern dürfen). Eine Testkriterienhierarchie schreibt dem Tester zwar vor, welche Eigenschaften seine 'fertige' Testfallmenge vorweisen muss, hilft dem Tester aber nicht bei der Identifikation der einzelnen Testfälle. Dabei genügt es nicht, wie im Falle sequentieller Tests, das Augenmerk auf die Testfälle allein zu richten: Testszenarien für parallele Module müssen zusätzlich Steuerungsinformationen zur gezielten Ausführungskontrolle der TUT (Threads Under Test) enthalten.
Im Jahr 2012 ist ein Framework für Java entstanden, das diese gezielte Ablaufsteuerung für TUT automatisch generiert. Der Tester muss lediglich die Byte-Code-Dateien seiner Applikation bereitstellen, weitere Details wie z.B. Quellcode oder Einschränkungen auf bestimmte Testszenarien kann er optional angeben, er muss sie aber nicht zwangsweise mühsam einpflegen. Der Ansatz verwendet Aspekt-Orientierte Programmierung, um die für typische Nebenläufigkeitsfehler verantwortlichen Speicherzugriffe (Lesen bzw. Schreiben von Variablen) mittels automatisch generierten Advices zu umschließen. Werden die Aspekte ins SUT (System Under Test) eingewoben, dann werden Variablenzugriffe zur Ausführungszeit abgefangen und die ausführenden Threads in der Ablaufsteuerung 'geparkt', bis das gewünschte Testszenario erreicht ist, und dann kontrolliert in der gewünschten Reihenfolge zur weiteren Ausführung reaktiviert. Zur Demonstration wurden einige naive Ablaufsteuerungen umgesetzt, die individuelle Variablenzugriffe z.B. gezielt abwechselnd verschiedenen Threads erlauben.
Der 2012 begonnene Prototyp des InThreaT-Framework wurde im Jahr 2013 zum Eclipse-Plugin umgebaut. Damit ist der Ansatz Multi-Projekt-fähig geworden und die erforderliche Funktionalität integriert sich nahtlos in die vertraute Entwicklungsumgebung (IDE) des Entwicklers bzw. des Testers. Darüber hinaus verringert sich für den Tester dadurch auch der Konfigurationsaufwand, der nunmehr ebenfalls intuitiv in der gewohnten IDE erfolgt - z.B. die Auswahl und Persistenz der im Test zu beobachtenden Verschränkungspunkte, welche schließlich Grundlage der automatische Variation der zu testenden Verschränkungen sind. Für die automatische Exploration der relevanten Verschränkungen bedarf es außerdem einer Infrastruktur zur Anreicherung von Testfällen mit Steuerungsinformationen zwecks kontrollierter (Wieder-)Ausführung einzelner Tests. Im Jahr 2013 wurde exemplarisch ein solcher Ansatz für JUnit untersucht und implementiert, bei dem einzelne Testmethoden und/oder ganze Testklassen mit geeigneten Annotationen versehen werden.
-
Automatische Testdatengenerierung zur Unterstützung inkrementeller modell- und codebasierter Testprozesse für hochzuverlässige Softwaresysteme
(Drittmittelfinanzierte Einzelförderung)
Laufzeit: 01.03.2006 - 31.10.2009
Mittelgeber: Bayerisches Staatsministerium für Wirtschaft, Infrastruktur, Verkehr und Technologie (StMWIVT) (bis 09/2013)Das Vorhaben mit dem Verbundpartner AFRA GmbH verfolgte das Ziel, deutlich über den Stand der Technik hinaus die Testphase hochzuverlässiger, insbesondere sicherheitskritischer Software zu automatisieren, um dadurch bei reduzierten Kosten die Erkennung von Restfehlern in komplexer Software zu erhöhen.Im Rahmen des vom Freistaat Bayern als Bestandteil der Software Offensive Bayern geförderten Vorhabens wurden neue Verfahren zur automatischen Testunterstützung entwickelt und in entsprechende Werkzeuge umgesetzt. Diese Verfahren ermöglichen eine signifikante Reduzierung des erforderlichen Testaufwands in den frühen Entwurfsphasen und erlauben, den Bedarf ergänzender, auf Codebetrachtungen basierender Überprüfungen rechtzeitig festzustellen. Die automatisierte Testprozedur wurde im realen medizintechnischen Umfeld beim Pilotpartner Siemens Medical Solutions erprobt.
Das Projekt war in zwei Teile gegliedert. Der erste Teil betrachtete die automatische Testdatengenerierung auf Komponentenebene, während der zweite Teil den Integrationsaspekt von Komponenten in den Vordergrund stellte und Verfahren zur Automatisierung des Integrationstests entwickelte. In beiden Fällen wurde ein am Lehrstuhl auf Codeebene bereits erfolgreich umgesetzte Testkonzept auf Modellebene übertragen.
Die erzielten Ergebnisse und Einsichten bildeten die Grundlage der Dissertation "Automatische Optimierung und Evaluierung modellbasierter Testfälle für den Komponenten- und Integrationstest" von Herrn Dr.-Ing. Florin Pinte.
Testen von Softwaresystemen
Grunddaten
| Titel | Testen von Softwaresystemen |
|---|---|
| Kurztext | TSWS |
| Turnus des Angebots | nur im Sommersemester |
| Semesterwochenstunden | 4 |
Parallelgruppen / Termine
1. Parallelgruppe
| Semesterwochenstunden | 4 |
|---|---|
| Lehrsprache | German |
| Verantwortliche/-r |
Jonas Butz Dr.-Ing. Norbert Oster |
| Zeitpunkt | Startdatum - Enddatum | Ausfalltermin | Durchführende/-r | Bemerkung | Raum |
|---|---|---|---|---|---|
| wöchentlich Di, 16:15 - 17:45 | 22.04.2025 - 22.07.2025 | 10.06.2025 22.04.2025 |
|
11302.01.153 | |
| wöchentlich Mi, 16:15 - 17:45 | 23.04.2025 - 23.07.2025 |
|
11302.01.153 |
Intensivübungen zu Parallele und Funktionale Programmierung
Grunddaten
| Titel | Intensivübungen zu Parallele und Funktionale Programmierung |
|---|---|
| Kurztext | PFP-IÜ |
| Turnus des Angebots | nur im Sommersemester |
| Semesterwochenstunden | 2 |
Parallelgruppen / Termine
1. Parallelgruppe
| Verantwortliche/-r |
Prof. Dr. Michael Philippsen Dr.-Ing. Norbert Oster |
|---|
| Zeitpunkt | Startdatum - Enddatum | Ausfalltermin | Durchführende/-r | Bemerkung | Raum |
|---|---|---|---|---|---|
| wöchentlich Fr, 10:15 - 11:45 | 18.07.2025 - 01.08.2025 |
|
11901.U1.245 |
2023
- , , , , :
Practical Flaky Test Prediction using Common Code Evolution and Test History Data
16th IEEE International Conference on Software Testing, Verification and Validation, ICST 2023 (Dublin, 16.04.2023 - 20.04.2023)
In: IEEE (Hrsg.): Proceedings - 2023 IEEE 16th International Conference on Software Testing, Verification and Validation, ICST 2023 2023
DOI: 10.1109/ICST57152.2023.00028
BibTeX: Download - , , , , :
Practical Flaky Test Prediction using Common Code Evolution and Test History Data [replication package]
figshare (2023)
DOI: 10.6084/m9.figshare.21363075
BibTeX: Download
(online publication)
2020
- , , :
MutantDistiller: Using Symbolic Execution for Automatic Detection of Equivalent Mutants and Generation of Mutant Killing Tests
15th International Workshop on Mutation Analysis (Mutation 2020) (Porto, 24.10.2020 - 24.10.2020)
In: 2020 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW) 2020
DOI: 10.1109/ICSTW50294.2020.00055
URL: https://mutation-workshop.github.io/2020/
BibTeX: Download
2017
- , , :
AuDoscore: Automatic Grading of Java or Scala Homework
Third Workshop "Automatische Bewertung von Programmieraufgaben" (ABP 2017) (Potsdam, 05.10.2017 - 06.10.2017)
In: Sven Strickroth Oliver Müller Michael Striewe (Hrsg.): Proceedings of the Third Workshop "Automatische Bewertung von Programmieraufgaben" (ABP 2017) 2017
Open Access: http://ceur-ws.org/Vol-2015/ABP2017_paper_01.pdf
URL: http://ceur-ws.org/Vol-2015/ABP2017_paper_01.pdf
BibTeX: Download
2011
- , :
Structural Equivalence Partition and Boundary Testing
Software Engineering 2011 - Fachtagung des GI-Fachbereichs Softwaretechnik (Karlsruhe, 24.02.2011 - 25.02.2011)
In: Ralf Reussner, Matthias Grund, Andreas Oberweis, Walter Tichy (Hrsg.): Lecture Notes in Informatics (LNI), P-183, Bonn: 2011
URL: https://www2.cs.fau.de/publication/download/SE2011-OsterPhilippsen-SEBT.pdf
BibTeX: Download
2008
- , , , :
Automatische Generierung optimaler modellbasierter Regressionstests
Workshop on Model-Based Testing (MoTes 2008) (München, 08.09.2008 - 13.09.2008)
In: Heinz-Gerd Hegering, Axel Lehmann, Hans Jürgen Ohlbach, Christian Scheideler (Hrsg.): INFORMATIK 2008 - Beherrschbare Systeme dank Informatik (Band 1), Bonn: 2008
BibTeX: Download - , , :
Techniques and Tools for the Automatic Generation of Optimal Test Data at Code, Model and Interface Level
30th International Conference on Software Engineering (ICSE 2008) (Leipzig, 10.05.2008 - 18.05.2008)
In: Companion of the 30th international conference on Software engineering (ICSE Companion '08), New York, NY, USA: 2008
DOI: 10.1145/1370175.1370191
URL: http://dl.acm.org/ft_gateway.cfm?id=1370191
BibTeX: Download - , , :
Automatic Generation of Optimized Integration Test Data by Genetic Algorithms
Software Engineering 2008 - Workshop "Testmethoden für Software - Von der Forschung in die Praxis" (München, 19.02.2008 - 19.02.2008)
In: Walid Maalej, Bernd Bruegge (Hrsg.): Software Engineering 2008 - Workshopband, Bonn: 2008
URL: http://www11.informatik.uni-erlangen.de/Forschung/Publikationen/TESO%202008.pdf
BibTeX: Download - , , :
White and Grey-Box Verification and Validation Approaches for Safety- and Security-Critical Software Systems
In: Information Security Technical Report 13 (2008), S. 10-16
ISSN: 1363-4127
DOI: 10.1016/j.istr.2008.03.002
URL: http://www.sciencedirect.com/science/article/pii/S1363412708000071
BibTeX: Download - , , :
Qualität und Zuverlässigkeit im Software Engineering
In: Zeitschrift für wirtschaftlichen Fabrikbetrieb 103 (2008), S. 407-412
ISSN: 0932-0482
URL: http://www.zwf-online.de/ZW101296
BibTeX: Download
2007
- :
Automatische Generierung optimaler struktureller Testdaten für objekt-orientierte Software mittels multi-objektiver Metaheuristiken (Dissertation, 2007)
URL: https://www.ps.tf.fau.de/files/2020/04/norbertoster_dissertation2007.pdf
BibTeX: Download - , :
Automatische Testdatengenerierung mittels multi-objektiver Optimierung
Software Engineering 2007 (Hamburg, 27.03.2007 - 30.03.2007)
In: Wolf-Gideon Bleek, Henning Schwentner, Heinz Züllighoven (Hrsg.): Software Engineering 2007 - Beiträge zu den Workshops, Bonn: 2007
URL: http://subs.emis.de/LNI/Proceedings/Proceedings106/gi-proc-106-007.pdf
BibTeX: Download - , , , :
Automatische, modellbasierte Testdatengenerierung durch Einsatz evolutionärer Verfahren
Informatik 2007 - 37. Jahrestagung der Gesellschaft für Informatik e.V. (GI) (Bremen, 24.09.2007 - 27.09.2007)
In: Rainer Koschke, Otthein Herzog, Karl H Rödiger, Marc Ronthaler (Hrsg.): Informatik 2007 - Informatik trifft Logistik, Bonn: 2007
URL: http://cs.emis.de/LNI/Proceedings/Proceedings110/gi-proc-110-067.pdf
BibTeX: Download - , (Hrsg.):
Computer Safety, Reliability, and Security
Berlin Heidelberg: 2007
(Lecture Notes in Computer Science, Bd. 4680)
ISBN: 978-3-540-75100-7
DOI: 10.1007/978-3-540-75101-4
URL: http://link.springer.com/content/pdf/10.1007%2F978-3-540-75101-4.pdf
BibTeX: Download - , , :
Interface Coverage Criteria Supporting Model-Based Integration Testing
20th International Conference on Architecture of Computing Systems (ARCS 2007) (Zürich, 12.03.2007 - 15.03.2007)
In: Marco Platzner, Karl E Grosspietsch, Christian Hochberger, Andreas Koch (Hrsg.): Proceedings of the 20th International Conference on Architecture of Computing Systems (ARCS 2007), Zürich: 2007
BibTeX: Download
2006
- , :
Automatic Test Data Generation by Multi-Objective Optimisation
25th International Conference on Computer Safety, Reliability and Security (SAFECOMP 2006) (Gdansk, 26.09.2006 - 29.09.2006)
In: Janusz Górski (Hrsg.): Computer Safety, Reliability, and Security, Berlin Heidelberg: 2006
DOI: 10.1007/11875567_32
URL: http://link.springer.com/content/pdf/10.1007%2F11875567.pdf
BibTeX: Download
2005
- :
Automated Generation and Evaluation of Dataflow-Based Test Data for Object-Oriented Software
Second International Workshop on Software Quality (SOQUA 2005) (Erfurt, 20.09.2005 - 22.09.2005)
In: Ralf Reussner, Johannes Mayer, Judith A. Stafford, Sven Overhage, Steffen Becker, Patrick J. Schroeder (Hrsg.): Quality of Software Architectures and Software Quality: First International Conference on the Quality of Software Architectures, QoSA 2005, and Second International Workshop on Software Quality, SOQUA 2005, Berlin Heidelberg: 2005
DOI: 10.1007/11558569_16
URL: http://link.springer.com/content/pdf/10.1007%2F11558569.pdf
BibTeX: Download
2004
- :
Automatische Generierung optimaler datenflussorientierter Testdaten mittels evolutionärer Verfahren
21. Treffen der Fachgruppe TAV [Test, Analyse und Verifikation von Software] (Berlin, 17.06.2004 - 18.06.2004)
In: Udo Kelter (Hrsg.): Softwaretechnik-Trends 2004
URL: http://pi.informatik.uni-siegen.de/stt/24_3/01_Fachgruppenberichte/TAV/TAV21P4Oster.pdf
BibTeX: Download - , :
A Data Flow Approach to Testing Object-Oriented Java-Programs
Probabilistic Safety Assessment and Management (PSAM7 - ESREL'04) (Berlin, 14.06.2004 - 18.06.2004)
In: Cornelia Spitzer, Ulrich Schmocker, Vinh N. Dang (Hrsg.): Probabilistic Safety Assessment and Managment, London: 2004
DOI: 10.1007/978-0-85729-410-4_180
URL: http://link.springer.com/chapter/10.1007%2F978-0-85729-410-4_180
BibTeX: Download
2002
- , , :
A Hybrid Genetic Algorithm for School Timetabling
AI2002 15th Australian Joint Conference on Artificial Intelligence (Canberra, 02.12.2002 - 06.12.2002)
In: Mc Kay B., Slaney J. (Hrsg.): AI 2002: Advances in Artificial Intelligence - 15th Australian Joint Conference on Artificial Intelligence, Berlin Heidelberg: 2002
DOI: 10.1007/3-540-36187-1_40
URL: http://www2.informatik.uni-erlangen.de/publication/download/AI02.ps.gz
BibTeX: Download
2001
- :
Implementierung eines evolutionären Verfahrens zur Risikoabschätzung (Diplomarbeit, 2001)
BibTeX: Download - :
Stundenplanerstellung für Schulen mit Evolutionären Verfahren (Studienarbeit (Vordiplom), 2001)
BibTeX: Download
| 2010-2019 | embedded world Conference, PC-Mitglied, Session-Chair |
| 2016-2019 | MINTerAKTIV/GIFzuMINTS, Co-Projektkoordinator |
| 2015 | Software Engineering 2015 (SE2015), PC-Mitglied |
| 2012-2014 | WEMUCS – Methoden und Werkzeuge zur iterativen Entwicklung und Optimierung von Software für eingebettete Multicore-Systeme, Co-Projektkoordinator |
| 2012/2013 | Mitglied der Berufungskommission W2-Professur Didaktik der Informatik (Nachfolge Brinda) |
| 2006-2008 | UnITeD – Unterstützung Inkrementeller TestDaten, Co-Projektkoordinator |
| 2007 | International Conference on Computer Safety, Reliability and Security (SAFECOMP 2007), Mitglied des Organisationskommitees |
Kurzbeschreibung:
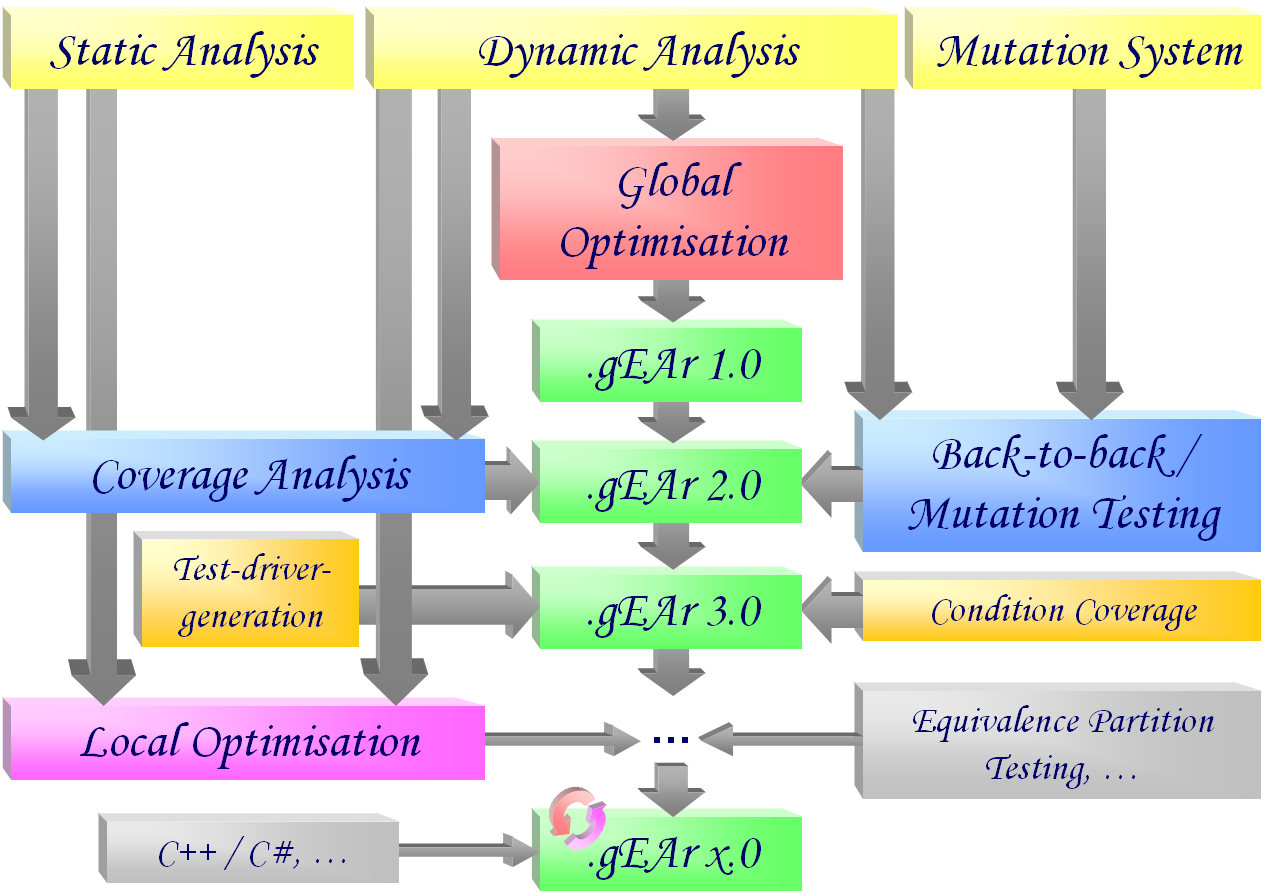
Die Zunahme der Komplexität moderner Softwaresysteme stellt trotz deutlich verbesserter Entwicklungsmethoden heute noch das Haupthindernis auf dem Weg zur fehlerfreien Programmerstellung dar. Größe und Budget heutiger Projekte verbieten meist eine vollständige formale Verifikation, die selbst in realisierbaren Fällen nur die logische Domäne der Programme und nicht ihr reales Umfeld einbezieht, weshalb dem Testen als Qualitätssicherungsmaßnahme vor der Freigabe der Software ein hoher Stellenwert eingeräumt wird. Um die Chancen der Fehlererkennung während der Testphase zu erhöhen, werden Testfälle nach unterschiedlichen Strategien ausgewählt: Während funktionales Testen die Eingaben aus den spezifizierten Anforderungen herleitet, streben strukturelle Tests eine möglichst vollständige Ausführung des Codes an. Bedingt durch die Komplexität der Kontrollstrukturen ist die Ermittlung geeigneter Testdaten zur Erfüllung datenflussorientierter Überdeckungskriterien besonders zeitaufwändig. Selbst wenn Testdaten zufällig generiert werden, müssen sie darüber hinaus meist manuell auf Korrektheit überprüft werden, so dass ihre Anzahl entscheidend zu Buche schlägt.
Ziel des laufenden Projekts ist es, die Generierung adäquater Mengen datenflussorientierter Testfälle zu automatisieren und unterschiedliche Verfahren hinsichtlich ihrer Eignung nach verschiedenen Kriterien (Güte, Aufwand) zu untersuchen. Als geeignete Such- und Optimierungsalgorithmen haben sich Evolutionäre Verfahren in unterschiedlichen Anwendungen erwiesen. Bisherige Arbeiten empfehlen bereits Genetische Algorithmen, jedoch wurde ihre Anwendbarkeit lediglich auf einfache Kontrollflusskriterien (etwa nach erzielten Anweisungs- oder Verzweigungsüberdeckungsmaßen) untersucht. Auch hat man bisher entweder eigene Programmiersprachen definiert oder bestehende soweit eingeschränkt, dass die Verfahren nicht mehr ohne weiteres auf reale Projekte übertragbar sind.
- Dynamische Analyse der Testausführung
Um die während der Ausführung eines Testfalls tatsächlich überdeckten Definitions- / Benutzungspaare (sogenannter def/use Paare) zu ermitteln, wurde ein Werkzeug zur Überwachung der dynamischen Ausführung eines Java-Programms entwickelt. Dieses Werkzeug instrumentiert den Quellcode des Testobjekts so, dass während eines einzelnen Testlaufs alle dazu relevanten Datenflussinformationen protokolliert werden. Die Ergebnisse wurden anlässlich der internationalen Tagung PSAM7/ESREL’04 publiziert. - Globale Optimierung von Testdatensätzen
Aufbauend auf der dynamischen Bewertung der von einem Testdatensatz erzielten Überdeckung wurde ein Verfahren entwickelt, um optimale Testdatensätze mittels klassischer und evolutionärer Suchstrategien zu generieren. Dabei werden Testdatensätze nach ihrem zu minimierenden Umfang sowie der zu maximierenden Anzahl der von ihnen überdeckten Datenflusspaare bewertet. Die erzielte globale Optimierung erfordert keine detaillierte Kenntnis der Kontrollflussstruktur des Testobjekts. Zur Generierung der Testdatensätze wurden unterschiedliche selbstadaptive Evolutionäre Verfahren sowie genetische Operatoren eingesetzt und vergleichend bewertet. Die verschiedenen Kombinationen wurden in einem parallelisierten, verteilten Werkzeug realisiert und getestet. Einzelheiten wurden von der GI-Fachgruppe TAV veröffentlicht. - Statische Analyse des Testobjekts
Zur Bewertung der relativen Güte der vom Evolutionären Verfahren ermittelten Ergebnisse wird zusätzlich zu den tatsächlich erreichten Überdeckungsmaßen (siehe dynamische Analyse) die Kenntnis der maximal erzielbaren Überdeckung benötigt, das heißt der Gesamtanzahl der von Tests auszuführenden Knoten, Kanten und Teilpfade des Kontrollflussgraphen. Zu diesem Zweck wurde ein statischer Analysator realisiert, welcher darüber hinaus auch die jeweiligen Definitionen und Benutzungen (sowie alle sie verbindenden DU-Teilpfade) jeder Variablen im datenflussannotierten Kontrollflussgraphen lokalisiert. Ergänzt um die Ergebnisse der dynamischen Analyse kann zum einen ein besseres Abbruchkriterium für die globale Optimierung definiert werden, zum anderen wird die im folgenden beschriebene lokale Optimierung unterstützt. - Bestimmung des Fehleraufdeckungspotentials der automatisch generierten Testfälle
Zusätzlich zur Bewertung der relativen Güte einer Testfallmenge im Sinne der Überdeckung (siehe statische Analyse) wurde im vorliegenden Projekt auch eine Schätzung der Qualität automatisch generierter Testfälle durch Betrachtung ihres Fehleraufdeckungspotentials angestrebt. Dazu wurde ein Back-to-back-Testverfahren nach dem Prinzip des Mutationstestens umgesetzt. Dabei werden repräsentative Fehler in das ursprüngliche Programm injiziert und das Verhalten der modifizierten Variante bei der Ausführung der generierten Testfälle mit dem der unveränderten Fassung verglichen. Der Anteil der verfälschten Programme, bei denen eine Abweichung im Verhalten aufgedeckt werden konnte, ist ein Indikator für das Fehleraufdeckungspotential der Testfallmenge. Die Ergebnisse der letzten beiden Teilaufgaben wurden anlässlich der internationalen Tagung SOQUA 2005 publiziert. - Ausdehnung des Ansatzes auf weitere Teststrategien
Das entwickelte Verfahren zur multi-objektiven Generierung und Optimierung von Testfällen lässt sich auch auf andere Teststrategien übertragen. Wählt man Überdeckungskriterien, welche zu den betrachteten datenflussorientierten Strategien orthogonal sind, ist die Erkennung anderer Fehlerarten zu erwarten. Im Rahmen eines Teilprojektes wurde beispielsweise ein Ansatz zur statischen Analyse des Testobjekts und dynamischen Analyse der Testausführung im Hinblick auf das Kriterium der Bedingungsüberdeckung entwickelt und implementiert. Ebenso wurde in einem weiteren Teilprojekt eine Unterstützung für das Kriterium der strukturellen Grenzwerttestüberdeckung umgesetzt, wodurch in Kombination mit den bestehenden Kriterien eine zusätzliche Erhöhung der Fehleraufdeckungsquote zu erwarten ist. - Ergänzung des Verfahrens um automatische Testtreibergeneratoren
Da für die automatische Generierung von Testfällen spezialisierte Testtreiber notwendig sind, welche sich nur bedingt zur manuellen Überprüfung der Testergebnisse eignen, wurde darüber hinaus im Rahmen eines Teilprojektes eine zweistufige automatische Testtreibergenerierung umgesetzt. Diese erstellt zunächst parametrisierbare Testtreiber, welche ausschließlich während der Testfalloptimierung eingesetzt werden, und übersetzt diese anschließend in die übliche jUnit-Syntax, sobald die generierten und optimierten Testdaten vorliegen. - Experimentelle Bewertung des entwickelten Werkzeugs
Die praktische Relevanz des entwickelten Verfahrens wurde in verschiedenen experimentellen Einsätzen erprobt und bewertet. Als Testobjekte dienten dabei Java-Packages mit bis zu 27 Klassen (5439 Codezeilen). Die nebenläufige Testausführung während der Generierung und Optimierung der Testfälle wurde auf bis zu 58 vernetzten Rechnern parallelisiert. Die Ergebnisse wurden anlässlich der internationalen Tagung SAFECOMP 2006 veröffentlicht.
- Erweiterung des Leistungsumfangs der automatischen Generierung
Zusätzlich zu den bereits unterstützten Testkriterien aus der Familie der Kontroll- und Datenflussstrategien, wird die Methode und das umgesetzte Werkzeug auf weitere Testverfahren ausgedehnt. Auf der Basis der bereits entwickelten Verfahren und Werkzeuge, ist zu untersuchen, wie die obigen Forschungsergebnisse unter Einsatz von fach-spezifischem Wissen dahingehend erweitert und verbessert werden können, um die Heuristiken schneller und effizienter zu gestalten – beispielweise unter Einsatz verteilter Evolutionärer Verfahren. - Portierung des Werkzeugs zur Unterstützung weiterer Programmiersprachen
Nachdem die Implementierung der automatischen Erstellung von Testtreibern und der Generierung und Optimierung von Testdaten für Java-Programme bereits erfolgreich abgeschlossen wurde, ist die breitere Anwendbarkeit des Werkzeugs in der Industrie dadurch zu erreichen, dass die Unterstützung weiterer Programmiersprachen angeboten wird. Dazu gehört insbesondere die im eingebetteten Bereich verbreitete Familie der Sprache C – darunter die aktuelleren Derivate C++ und C#. Aufbauend auf den bisherigen Erkenntnissen für Java wird das bestehende Werkzeug um eine statische und eine dynamische Analyse für C#-Programme ergänzt. - Generierung zusätzlich erforderlicher Testdaten mittels lokaler Optimierung
Aus der bereits erfolgten Lokalisierung der Datenflusspaare (siehe statische Analyse) lassen sich insbesondere die für die Erfüllung des Testkriteriums fehlenden Testpfade ermitteln. Zugehörige Testfälle sollen durch die Anwendung Evolutionärer Verfahren in einer lokalen Optimierung generiert werden. Dazu wird eine neue Fitnessfunktion aufgrund graphentheoretischer Eigenschaften des Kontrollflussgraphen definiert. Die bereits umgesetzte Instrumentierung (dynamische Analyse) des Testobjekts wird passend erweitert. Somit wird die automatische Generierung der Testfälle gezielter lokal gelenkt und hinsichtlich Zeitaufwand und erzielter Datenflussabdeckung weiter verbessert.
- Download: Dissertation (PDF)